欢迎加入本站的kubernetes技术交流群,微信添加:加Blue_L。
vxlan网络
vxlan是一种基于3层网络实现的2层overlay网络。vxlan网络可以使用VNI划分出多个彼此隔离的网络,可应用于多租户场景。
vxlan可以结合bridge一起来使用,相当于使用vxlan将多个主机上的bridge连接起来形成一个大的逻辑上的bridge设备。也可以不使用bridge,而是结合路由使用。下图是结合路由或bridge使用的场景示例:
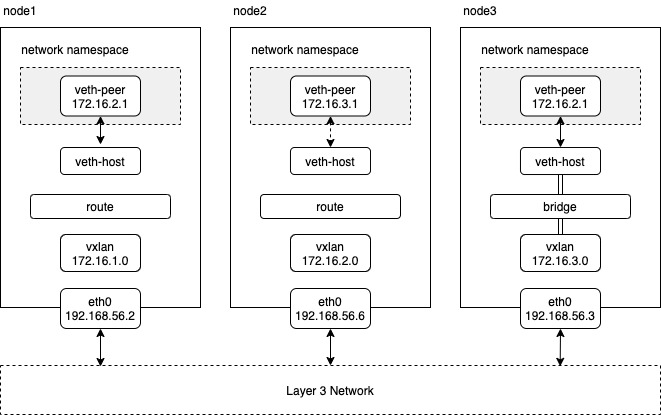
在kubernetes环境中,可以使用简单的路由方式。内核在vxlan数据包解包后将原始二层数据给到了vxlan设备去接收,vxlan设备将数据包送入到上层网络协议栈。网络协议栈根据主机上的路由表配置,将包发给相应pod的网卡。
在这种路由模式下,节点上不需要知道其他所有pod的mac地址,只需要节点上对应的网关的地址的mac。数据包通过vxlan设备发送和接收的大致流程如下:
数据发送:
- 数据包从pod1发出,进入peer网卡的接收队列,然后到达node1的协议栈,经过路由判决,走node1的forward链。
- forward时,要去的pod2的IP为172.16.2.1,主机路由匹配到应该走vxlan设备,下一跳为172.16.2.0。
- 数据包到达vxlan设备,查询路由表得知网关地址为172.16.2.0,于是通过arp协议查找网关的mac地址,在arp表中找到了匹配的记录后完成mac头封装,准备发送。
- vxlan设备发送数据包并不是提交到发送队列,而是调用udp隧道相关接口将数据包封装成一个udp数据包,接着会查询fdb表查找要将数据从那个VTEP接口发出,经过查找后得到的VTEP接口为192.168.56.2,从而将数据包发送node2节点 。
数据接收:
- node2接收后,走主机协议栈,判断这是发往本机的udp包,于是走INPUT方向,最终发到UDP隧道层处理。
- 当创建vxlan创建udp隧道时,会将其接收数据包方法覆盖为vxlan的接收方法,所以在收到vxlan的UDP数据包后,进行对vxlan包解包,之后调用网卡的接收数据包方法进行接收原始二层数据包,此时如果vxlan设备被加入到了bridge设备,那么这个数据包会由bridge设备收到,bridge设备决定进行二层抓发或是送入上层网络协议栈。如果没有加入bridge中,那么如果目的mac地址是自己的也会送入上层网络协议栈。
- 进入上层网络协议栈后,就会根据主机的路由判断是入站还是转发,发现目标地址是172.16.2.1,经过路由判决时,发现不是本机地址,进行转发,找到相应的路由通过veth-pairhost端发出,从而进入pod。
下面,我们通过一些列命令手动创建和管理vxlan设备,进行测试vxlan相关功能,此处我们采用纯路由方式。
首先在第一台主机上先创建vxlan设备,配置路由:
set -ux
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.ipv4.conf.all.proxy_arp=1
sysctl -w net.ipv4.conf.all.rp_filter=0
iptables -A FORWARD -d 172.16.0.0/16 -j ACCEPT
iptables -A FORWARD -s 172.16.0.0/16 -j ACCEPT
ip link add vxlan.1 type vxlan vni 1
ip link set vxlan.1 up
ip addr add 172.16.1.0/32 dev vxlan.1
ip route add 172.16.2.0/24 via 172.16.2.0 dev vxlan.1 onlink
ip netns add test3
ip link add name veth3 type veth mtu 1450 peer name br-veth3 mtu 1450
ip link set br-veth3 up
ip link set netns test3 dev veth3
ip route add 172.16.1.1/32 dev br-veth3
ip netns exec test3 ip link set veth3 up
ip netns exec test3 ip addr add 172.16.1.1/24 dev veth3
ip netns exec test3 ip route add 169.254.1.1 dev veth3
ip netns exec test3 ip route add default via 169.254.1.1 dev veth3 src 172.16.1.1在第二台设备上进行类似操作
set -ux
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.ipv4.conf.all.proxy_arp=1
sysctl -w net.ipv4.conf.all.rp_filter=0
iptables -A FORWARD -d 172.16.0.0/16 -j ACCEPT
iptables -A FORWARD -s 172.16.0.0/16 -j ACCEPT
ip link add vxlan.1 type vxlan vni 1
ip link set vxlan.1 up
ip addr add 172.16.2.0/32 dev vxlan.1
ip route add 172.16.1.0/24 via 172.16.1.0 dev vxlan.1 onlink
ip netns add test3
ip link add name veth3 type veth mtu 1450 peer name br-veth3 mtu 1450
ip link set br-veth3 up
ip link set netns test3 dev veth3
ip route add 172.16.2.1/32 dev br-veth3
ip netns exec test3 ip link set veth3 up
ip netns exec test3 ip addr add 172.16.2.1/24 dev veth3
ip netns exec test3 ip route add 169.254.1.1 dev veth3
ip netns exec test3 ip route add default via 169.254.1.1 dev veth3 src 172.16.2.1上面我们在两台主机上创建好了vxlan设备,子网路由和veth-pari的ip地址和默认路由。现在手动想系统添加arp表和fdb表。在第一台节点上执行
# 此处的mac地址是另一台主机上ip a命令查看得到
arp -s 172.16.2.0 2a:c5:85:90:a7:65 -i vxlan.1
bridge fdb append 2a:c5:85:90:a7:65 dev vxlan.1 dst 192.168.56.2在第二台主机上执行
# 此处的mac地址是第一台主机上ip a命令查看得到
arp -s 172.16.1.0 9e:e9:bd:69:a1:a9 -i vxlan.1
bridge fdb append 9e:e9:bd:69:a1:a9 dev vxlan.1 dst 192.168.56.6ipip网络
ipip是属于ip层封装ip层,属于ip隧道技术的一种,类似技术还有gre等。ip协议中的protocol字段设置为IPIP,这样就可以通过ip网络封装ip数据包,主机收到数据根据protocol对数据包进行拆包,并将原始数据包送入到网络协议栈。要使用ipip,需要加载下列内核模块。
[root@localhost ~]# lsmod | grep ipip
Module Size Used by
ipip 13465 0
tunnel4 13252 1 ipip
ip_tunnel 25163 1 ipip内核模块加载后在主机上会默认创建一个tunl0设备,可以直接使用这个设备。当然也可以自己创建一个自己的tunnel设备:
ip tunnel add mytunl0 mode ipip local 192.168.56.2当有了隧道设备之后就可以进行组网了,按照下图所示结构,为两台机器组建下面的网络结构。
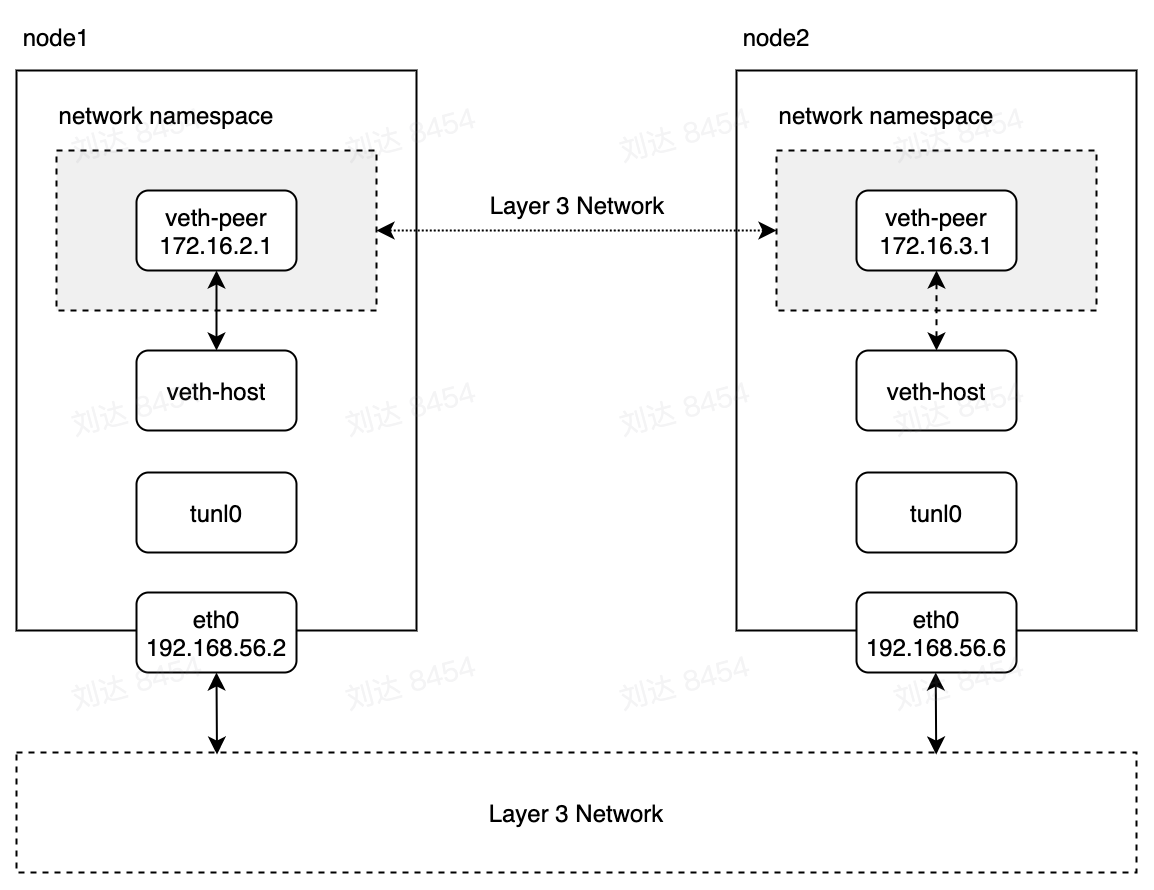
首先需要在两台主机上加载ipip内核模块:
modprobe ipip
ip link set tunl0 up在node1主机上veth-pair网络的路由规则,其中的dev指定数据包发送通过tunl0设备,src属性决定了主机上客户端默认绑定的ip地址。onlink表示下一跳地址直接与tunl0设备连接,不需要做网关是否与tunl0属于同一个网络的检查。然后我们再创建一个dummy网卡,分配该主机veth-pair网络下的某个ip地址。
[root@localhost ~]# ip route add 172.16.3.0/24 via 192.168.56.6 dev tunl0 src 192.168.56.6 onlink
[root@localhost ~]# ip link add dummy0 type dummy
[root@localhost ~]# ip addr add 172.16.2.1 dev dummy0
[root@localhost ~]# ip route add 172.16.2.1 dev dummy
[root@localhost ~]# ip link set dummy up在node2节点上执行类似操作:
[root@localhost ~]# ip link set tunl0 up
[root@localhost ~]# ip route add 172.16.2.0/24 via 192.168.56.2 dev tunl0 src 192.168.56.2 onlink
[root@localhost ~]# ip link add dummy0 type dummy
[root@localhost ~]# ip addr add 172.16.3.1 dev dummy0
[root@localhost ~]# ip route add 172.16.3.1 dev dummy
[root@localhost ~]# ip link set dummy up在node1节点上启动监听进行测试
[root@localhost ~]# nc -kl 172.16.2.1 8888在node2节点上去连接
[root@localhost ~]# nc -s 172.16.3.1 172.16.2.1 8888可以看到两边的nc可以正常通信。可使用抓包工具对网络数据包进行分析。
tcpdump -vvvnnn -i tunl0
# 或抓取主机网卡的数据包
tcpdum -vvvnnn -i enp0s3 host 192.168.56.6
# 或根据目的ip抓取ipip单向报文
tcpdump -i enp0s3 "ip proto 4 and (ip[20+16:1]=172 and ip[20+17:1]=16 and ip[20+18:1]=3 and ip[20+19:1]=1)"
# 或双向报文
tcpdump -i enp0s3 "ip proto 4 and ( (ip[20+12:1]=172 and ip[20+13:1]=16 and ip[20+14:1]=3 and ip[20+15:1]=1) or (ip[20+16:1]=172 and ip[20+17:1]=16 and ip[20+18:1]=2 and ip[20+19:1]=1) )"上面的例子中通过单独设置了主机上dummy网卡的路由实现了veth-pair网络互通,实际使用时也可再结合bridge设备使用,将veth-pair的host端都加入到bridge,然后设备主机的veth-pair网络的路由到bridge设备。
ip route add 172.16.3.0/24 dev br0ipip网络也属于overlay网络,在实际使用时要注意网卡mtu的配置。比如容器端网卡mtu要配置为1500-20=1480。对于节点上的网络配置TCPMSS,如通过iptables配置:
iptables -t mangle -A FORWARD -p tcp --tcp-flags SYN,RST SYN -o tunl0 -j TCPMSS --set-mss 1440直接路由
直接路由模式即数据包走主机的路由不经过封包,直接通过主机网络发出去。直接路由模式下,虚拟网络和主机网络属于一个网络平面,各个节点充当网关的作用,根据节点本身的路由规则将数据包转发给本机上相应的虚拟网络节点。直接路由要求各个节点都在同一个子网下,各个节点的主机网络通信不经过主机的网关。
在直接路由模式下,虚拟网络数据包通过主机网络的二层协议直接将数据包发给相应主机的网卡设备。在主机接收到数据包后mac地址为本地,不需要转发,将数据包上升到网络层。网络层根据本机路由配置将数据包转发给对应的网络接口。
直接路由模式下,接收到的数据包会经过netfilter(或iptables)的PREROUTING,FORWARD和POSTROUTING点,会触发执行相应的动作。发送端的数据包会经过OUTPUT和POSTROUTING点。
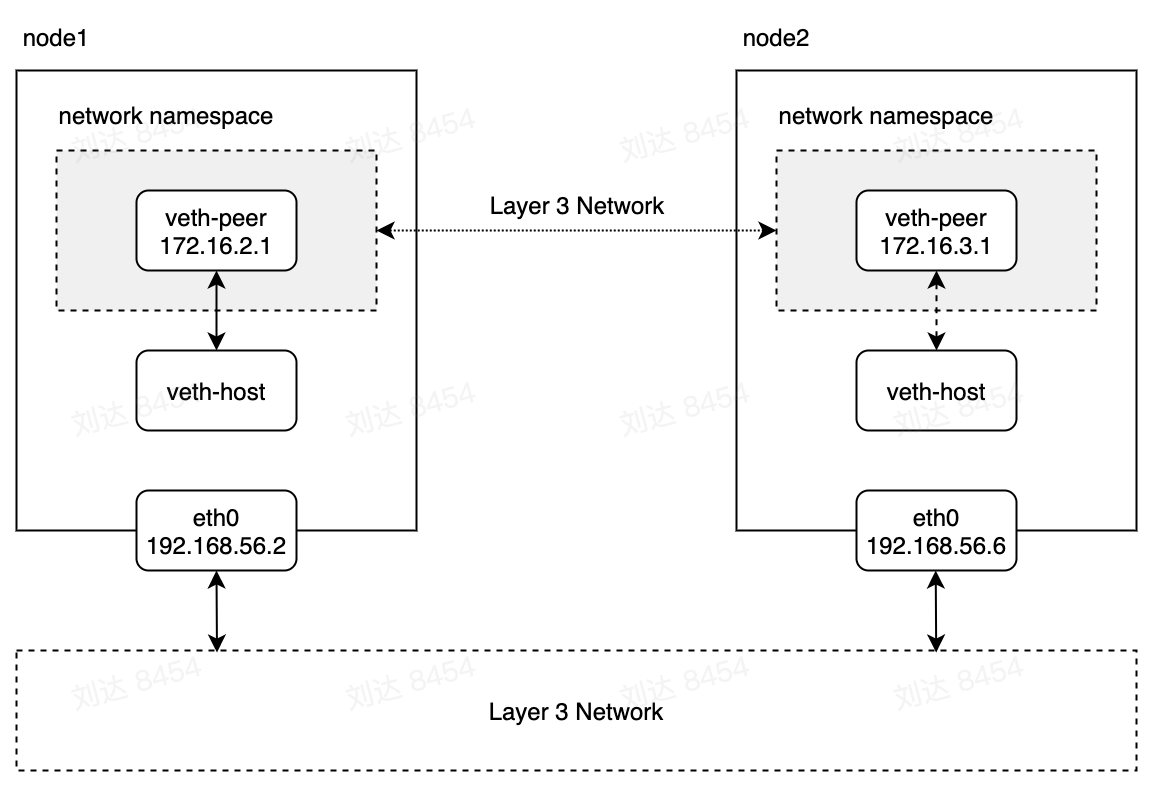
直接路由模式下也可以结合bridge使用,本机节点上的目标虚拟网络直接路由到bridge设备。
BGP网络
边界网关协议(英语:Border Gateway Protocol,缩写:BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。
大多数互联网服务提供商必须使用BGP来与其他ISP创建路由连接(尤其是当它们采取多宿主连接时)。因此,即使大多数互联网用户不直接使用它,但是与7号信令系统——即通过PSTN的跨供应商核心响应设置协议相比,BGP仍然是互联网最重要的协议之一。特大型的私有IP网络也可以使用BGP。例如,当需要将若干个大型的OSPF(开放最短路径优先)网络进行合并,而OSPF本身又无法提供这种可扩展性时。使用BGP的另一个原因是其能为多宿主的单个或多个ISP网络提供更好的冗余。
AS就是一个独立管理的网络。大公司或者组织的网络一般是由一到多个AS组成,小的公司或者个人是通常会接入到ISP(Internet Service Provider)的AS。不管怎么样,如果设备在互联网上,那么必定是属于某一个AS。EBGP是用来连接各个AS,这样互联网上的设备的才能够彼此互连。AS之间的连接协议,目前在用的,有且仅有EBGP一种。
IBGP应用在AS内部,作为IGP的一种。一般的IGP,例如OSPF,EIGRP,用来在邻接路由器之间传递路由。而IBGP可以用来在edge router之间同步路由,edge router并不需要邻接。Edge router是指在AS边缘,用来连接其他AS的router,那么edge router肯定是运行了EBGP。同时这个edge router也会有对端AS的路由。通过IBGP,edge router会将学习到的对端AS的路由,传递给其他的edge router。这样,可以实现跨AS的连通。
在下图中,AS1和AS2是两个不同的自治系统。r1,r2和r3在两个自治系统中作为边界路由器。AS2中的r1,r2与AS1中的r3通过ebgp协议交换路由信息同步两个系统的路由信息。而AS2中的r1和r2通过ibgp协议同步交换该自治系统中的内部路由信息。
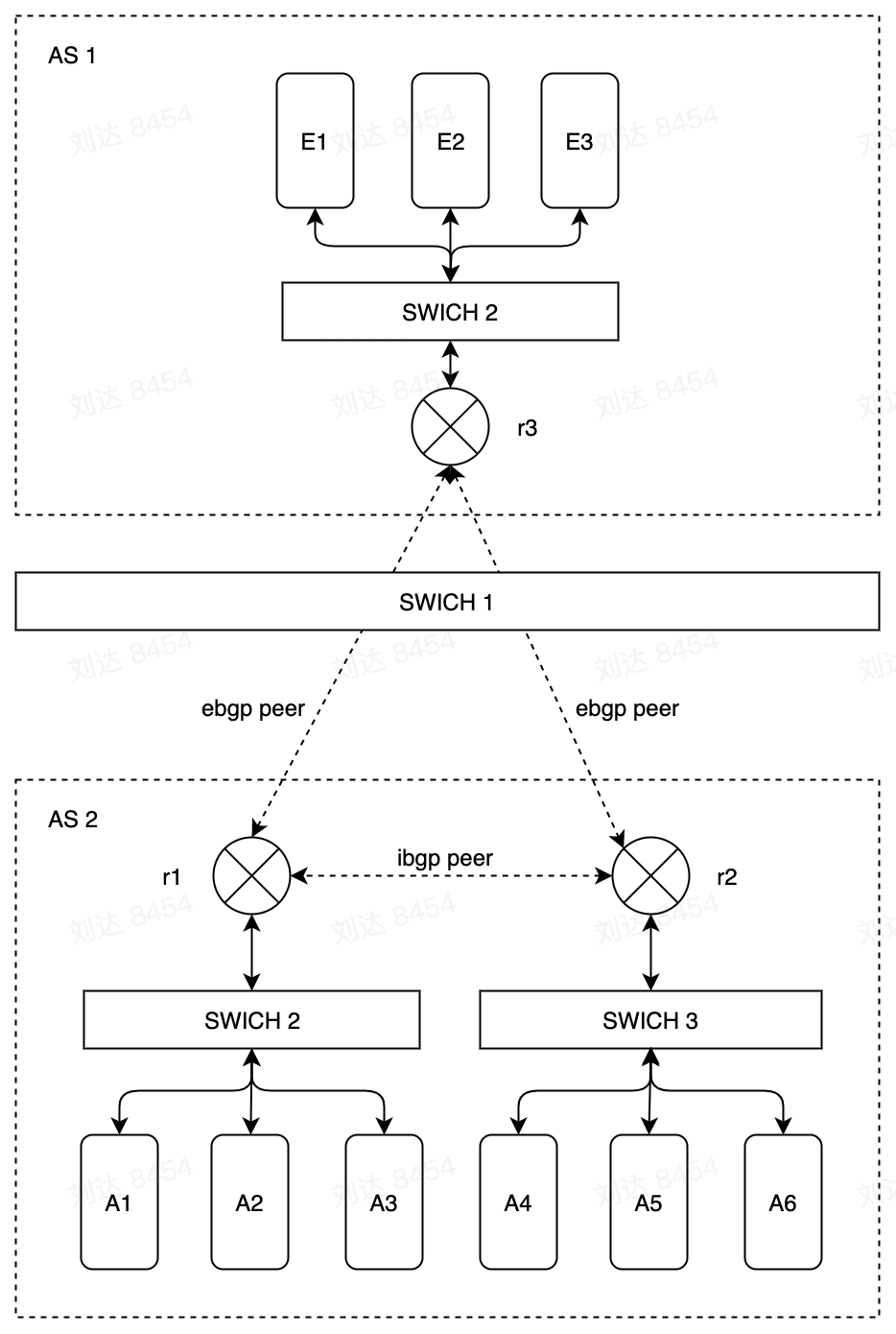
在kubernetes集群中,集群内各个节点都是bgp peer(上图中的router),运行bgp软件,通过协议将本机上pod的路由信息传递给其他节点上的peer端,其他节点会计算并配置改节点上的路由规则。集群内的每个节点之间可以互相建立peer连接,组成mesh。也可以使用其中数个节点作为reflector,其他所有节点连接到relfector,减少大规模集群中peer链接数量,reflector会将其他节点同步给自己的路由信息分发到其他节点上。
VPC路由
vpc路由一般是云控制器实现,也可以是flannel或cilium这类插件实现。云控制器读取节点的spec.PodCidrs字段,为这些网段在vpc内创建路由规则。节点上的cni也是使用PodCidrs字段下为pod分配ip地址,节点上可以使用bridge,也可以不使用bridge,kubernetes内置的kubenet模式是默认使用bridge插件。