欢迎加入本站的kubernetes技术交流群,微信添加:加Blue_L。
flannel支持host-gw,vxlan,ipip,ipsec模式和VPC路由模式。
部署
使用下面命令对部署flannel到集群中,会在集群中创建flannel的daemonset和一个flannel的配置文件。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml其中默认配置文件内容如下,主要包含了cni配置和网络配置。其中cni配置为采用flannel cni,指定网桥名称为cbr0,打开网桥接口的haripin模式,并将网桥设置为默认的网关。这些参数的含义可参考后面cni部分。
默认也指定了集群的网络模式为vxlan,使用flannel cni,并配置了整个网络的网段。
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.248.0.0/13",
"Backend": {
"Type": "vxlan"
}
}cni插件
cni要解决的问题是本机如何访问pod以及外部主机进来的数据包怎么进入pod。使用flannel作为网络插件的话,可选两种cni插件,其一是flannel cni,另外则是canal使用的calico cni。两个cni都会设置开启下面的ip转发。
# flannel cni -> bridge
/proc/sys/net/ipv4/ip_forward=1
/proc/sys/net/ipv6/conf/all/forwarding=1
# calico
/proc/sys/net/ipv4/conf/{vethname}/forwarding=1
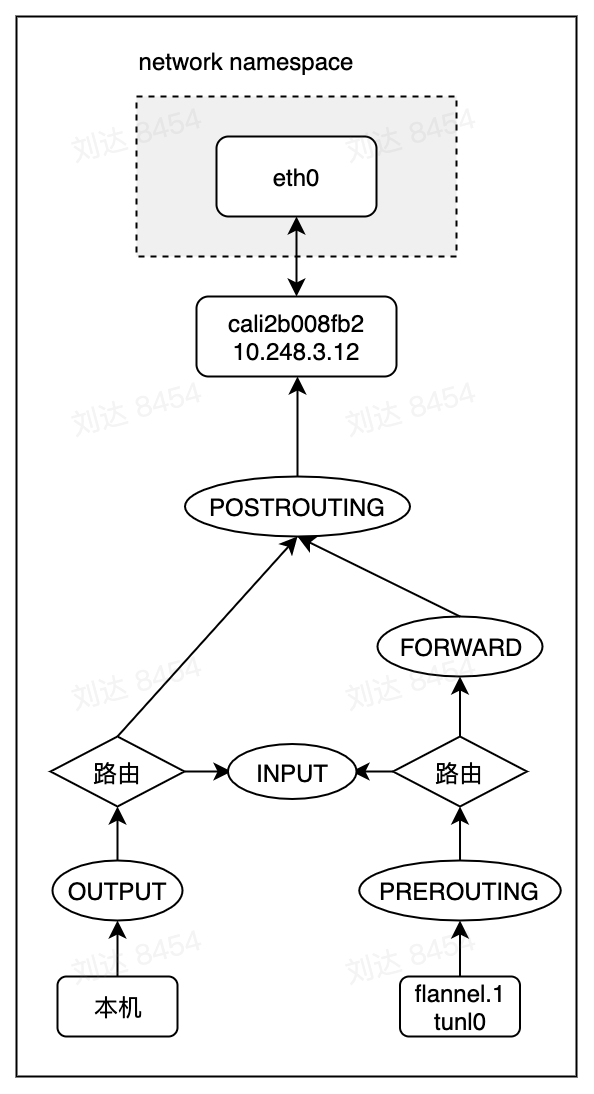
/proc/sys/net/ipv6/conf/{vethname}/forwarding=1在calico cni的情况下,calico通过路由方式实现数据包进入pod。如下面所示:
[root@node1 ~]# ip route | grep cali
10.248.3.232 dev cali443e68561ea scope link
10.248.3.233 dev calicc83f4493f4 scope link可以看到calico并不是给cali*网卡配置相应的ip地址,是因为本地发起访问数据包直接通过lo回环接口又回到了网络层,外部访问也是进入到了网络层。通过路由而不是通过配置ip是为让数据包流入host端的veth-pair。
在使用flannel cni的情况下,除了创建和配置veth-pair之外,还会额外创建一个bridge,并将host端加入到bridge。加入到bridge时,host端接口的包都被bridge接收,走二层转发,arp寻找对方mac。
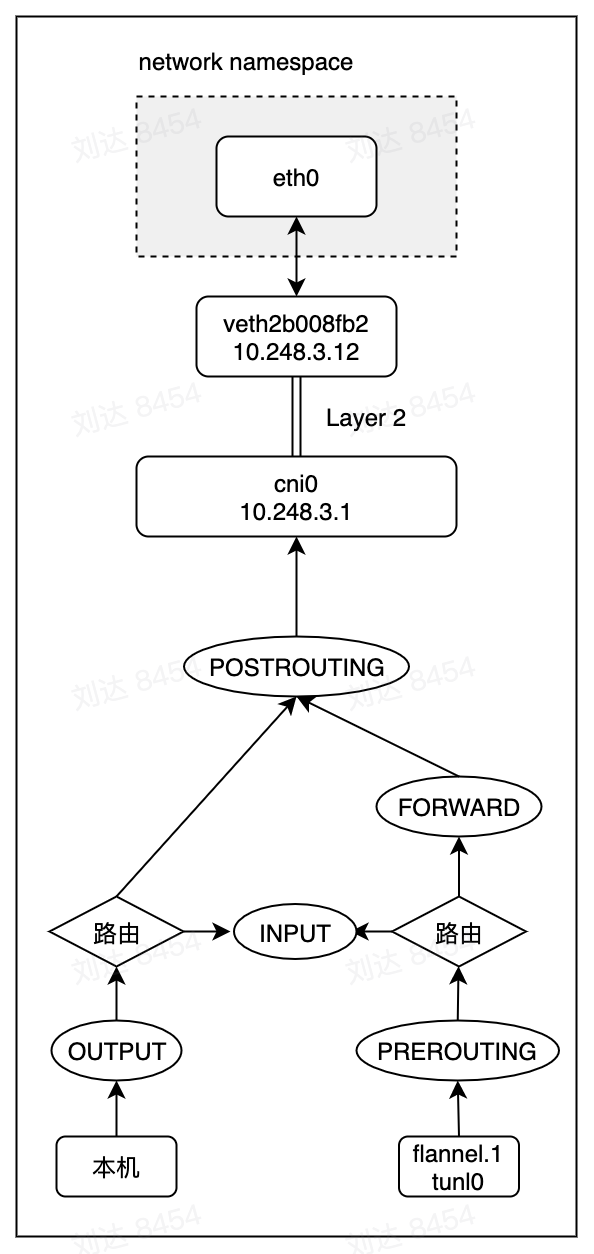
flannel cni
flannel的cni配置主要是申请配置网卡加入到网络中和从网络中删除。flannel cni插件本身实现这些功能是通过delegate实现的,网络接口设备的管理是通过bridge插件,而ip地址管理是通过host-local插件实现,这些都是内置在flannel cni中的逻辑。在flannel cni中主要逻辑是将获取flannel网络相关的配置信息,转换为bridge和host-local所依赖的配置。
flanneld会在每个节点上写入一个/run/flannel/subnet.env(默认)的文件,里面记录了当前节点在网络中的配置,如:
cat /var/run/flannel/subnet.env
# 整个网络的网段
FLANNEL_NETWORK=10.248.0.0/13
# 该节点上pod网段
FLANNEL_SUBNET=10.248.1.0/24
# 网卡mtu,vxlan的话要用主机网卡mtu-50
FLANNEL_MTU=1500
# 使用使用ip地址转换,kube-proxy也有这个配置,他们两个一个配置了就行
FLANNEL_IPMASQ=trueflannel cni在执行时,会读入这个配置信息,将其中的FLANNEL_NETWORK会加入到pod网卡认路由配置中,FLANNEL_SUBNET,FLANNEL_MTU,FLANNEL_IPMASQ会传递给bridge插件,作为bridge的配置或配置masquerade规则。
flannel还会将特定pod配置cni时使用的配置保存到系统的/var/lib/cni/flannel(默认)目录下,以便后面删除该pod时使用相同的cni配置。
下面是flannel cni配置列表参考,下面一些配置是flannel动态生成的,这里按照cni规范展示出来方便理解。此处的配置会覆盖subnet.env中的配置:
{
"type": "flannel",
"delegate": {
## 如果不指定则为bridge
# "type": "bridge",
## 此处的参数都会传给bridge插件
"hairpinMode": true,
"isDefaultGateway": true
## isGateway不指定flannel则默认设置为true
## bridge插件发现isDefaultGateway=true,会重新设置isGateway=true
# "isGateway": true,
"ipMasq": true,
"mtu": 1450,
## ipam相关参数,flannel基于subnet.env来的
# "ipam": {
# "type": "host-local",
# "subnet": 10.248.2.0/24,
# "routes": [
# "10.248.0.0/13"
# ]
# },
},
}
}基于上面匹配值,我么可以登录到集群的节点上手动调用cni插件来创建和配网络接口。
ip netns add cni-test
cat <<EOF > config
{
"name": "cbr0",
"cniVersion": "0.3.1",
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
}
EOF
CNI_COMMAND=ADD CNI_CONTAINERID=1234 CNI_NETNS=/var/run/netns/cni-test CNI_IFNAME=eth0 CNI_PATH=/opt/cni/bin/ /opt/cni/bin/flannel < configcalico cni
如果集群的网络插件用的是canal,则cni的配置为canal的。canal使用了flannel的网络,calico的cni,支持网络策略。但是现在calico也支持vxlan,ipip等网络,所以新集群可以抛弃canal了。
{
"type": "calico",
"log_level": "debug",
"log_file_path": "/var/log/calico/cni/cni.log",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"mtu": __CNI_MTU__,
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "__KUBECONFIG_FILEPATH__"
}
}vxlan模式详解
网络配置
net-conf.json: |
{
"Network": "10.248.0.0/13",
"Backend": {
"Type": "vxlan",
"VNI": 1,
"Port": 8472,
"DirectRouting": true
}
}配置中Type为vxlan,VNI标识vxlan网络标识,可以支持2^24个。Port配置的是vxlan设备的VTEP虚拟接口对端的UDP端口号。DirectRouting如果是同子网是否走直接路由。一般配置上Type为vxlan就可以了。
如果集群使用的canal的话,cni插件则为calico,主机上网络接口的管理都由calico负责。flannel只负责集群跨节点的网络,则整体组件结构为:
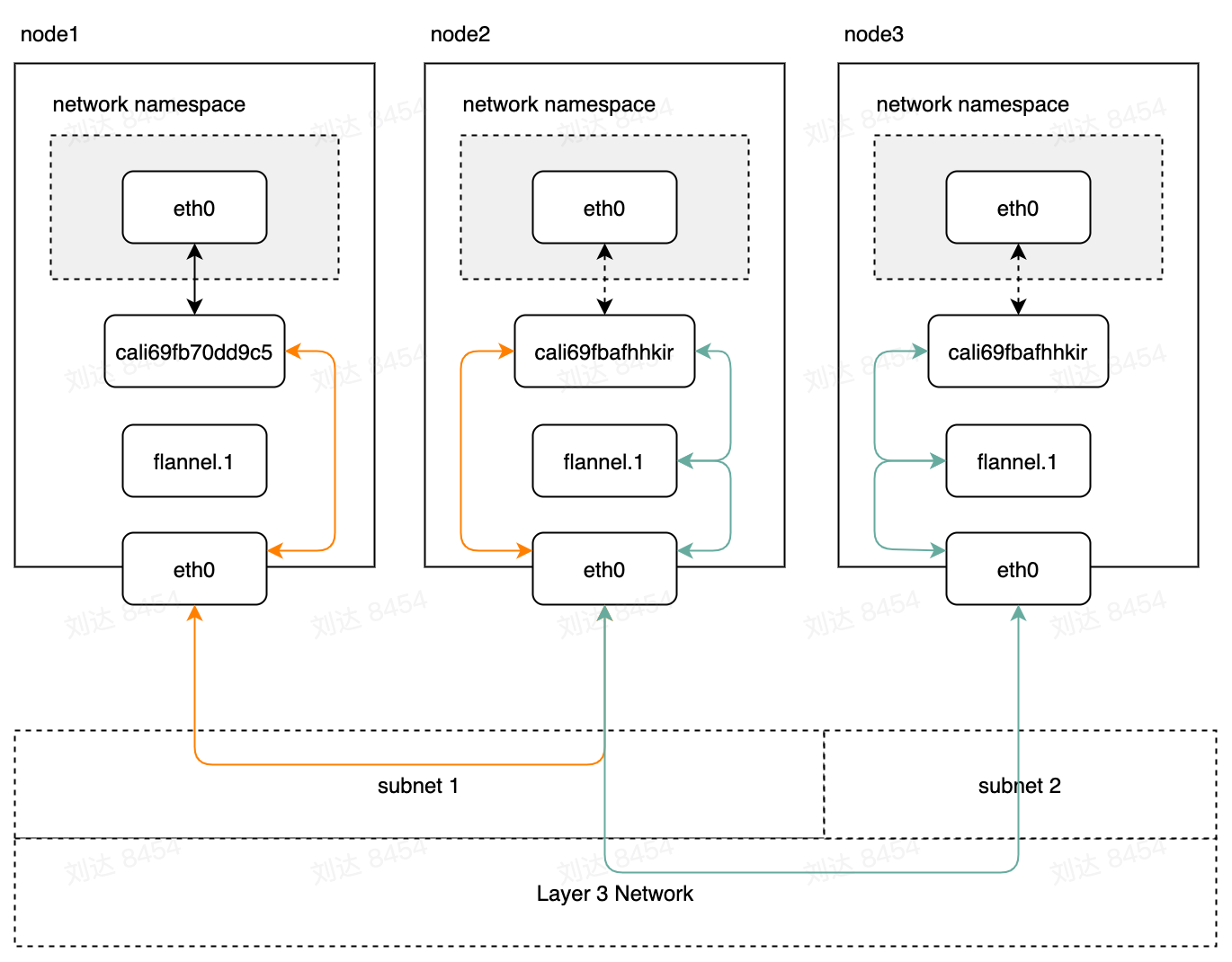
当开启了DirectRouting配置项后,flannel可以根据根据k8s中node资源的annotation里的PublicIP来感知是否可以进行直接路由,其原理是获取对方节点的路由规则,如果规则中配置了网关地址,则说明不可以直接路由,否则的话他们就是属于同一个LAN,可以直接路由。如果可以直接路由则会生成类似这些规则:
10.248.3.0/24 via 192.168.56.2 dev enp0s3如果不是走直接路由,则是通过vxlan封包通过命令可以看到flannel创建出来的vxlan设备以及对各个节点上pod子网创建的路由规则。可以看到其中10.248.1.0/24这个子网的路由网关为10.248.1.0,从flannel.1网卡发出。注意看这个路由规则里的onlink配置。pod的网卡eth0发出的(即veth-pair进入内核)的数据包都会走这个路由。
[root@master1 ~]# ip a
4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 4a:f4:02:16:3c:5f brd ff:ff:ff:ff:ff:ff
inet 10.248.0.0/32 brd 10.248.0.0 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::48f4:2ff:fe16:3c5f/64 scope link
valid_lft forever preferred_lft forever
[root@master1 ~]# ip route | grep flannel.1
10.248.1.0/24 via 10.248.1.0 dev flannel.1 onlink
10.248.2.0/24 via 10.248.2.0 dev flannel.1 onlink
10.248.3.0/24 via 10.248.3.0 dev flannel.1 onlink
10.248.4.0/24 via 10.248.4.0 dev flannel.1 onlink
10.248.5.0/24 via 10.248.5.0 dev flannel.1 onlinkvxlan设备数据发送数据的大体流程参考如下:
- 查询路由表获取目的IP的网关(即其他节点上的flannel.1设备地址)
- 获取网关IP的MAC地址(arp),配置到原始二层头
- 进入到链路层,获取网关MAC地址所在的VTEP端口(fdb)
- 使用vxlan协议进行封包传递给udp隧道层
- 后vxlan封包后的数据包发到对应节点上。
收数据包的大体流程为:
- 收方内核对vxlan数据解包,得到VNI
- 根据VNI找到对应的vxlan设备,关联skb为该接口
- 调用内部方法重新接收数据包
- 后面走普通的网卡收包程序
在早期版本的flannel中,查找目的IP的mac地址和mac地址对应VTEP是通过内核触发的l3miss和l2miss事件实现的,当内核触发这些miss事件之后,执行flannel相关函数返回相应的结果。后面版本依次移除了这种miss事件机制。而是采用了直接对系统上arp表和fdb表编程,将它所知道的信息及时的配置到系统上。如下面所示:
[root@master1 ~]# arp -i flannel.1
Address HWtype HWaddress Flags Mask Iface
10.248.5.0 ether 16:d2:7c:90:7f:41 CM flannel.1
10.248.4.0 ether 2e:8d:a1:6e:b6:b7 CM flannel.1
10.248.1.0 ether 66:09:7b:11:c6:b5 CM flannel.1
10.248.3.0 ether 7e:ef:35:ca:65:32 CM flannel.1
10.248.2.0 ether 0e:c3:75:cc:17:45 CM flannel.1
[root@master1 ~]# bridge fdb show dev flannel.1
7e:ef:35:ca:65:32 dst 192.168.3.27 self permanent
0e:c3:75:cc:17:45 dst 192.168.3.31 self permanent
66:09:7b:11:c6:b5 dst 192.168.3.30 self permanent
2e:8d:a1:6e:b6:b7 dst 192.168.3.32 self permanent
16:d2:7c:90:7f:41 dst 192.168.3.28 self permanent此外,flannel还会创建下列iptables规则:
[root@master1 ~]# iptables -tfilter -S | grep 10.248
-A FORWARD -s 10.248.0.0/13 -j ACCEPT
-A FORWARD -d 10.248.0.0/13 -j ACCEPT
[root@master1 ~]# iptables -tnat -S | grep 10.248 | grep -v KUBE
-A POSTROUTING -s 10.248.0.0/13 -d 10.248.0.0/13 -j RETURN
-A POSTROUTING -s 10.248.0.0/13 ! -d 224.0.0.0/4 -j MASQUERADE
-A POSTROUTING ! -s 10.248.0.0/13 -d 10.248.0.0/24 -j RETURN
-A POSTROUTING ! -s 10.248.0.0/13 -d 10.248.0.0/13 -j MASQUERADE
[root@master2 ~]# iptables -tnat -S | grep 10.248 | grep -v KUBE
-A POSTROUTING -s 10.248.0.0/13 -d 10.248.0.0/13 -j RETURN
-A POSTROUTING -s 10.248.0.0/13 ! -d 224.0.0.0/4 -j MASQUERADE
-A POSTROUTING ! -s 10.248.0.0/13 -d 10.248.1.0/24 -j RETURN
-A POSTROUTING ! -s 10.248.0.0/13 -d 10.248.0.0/13 -j MASQUERADEipip模式详解
网络配置
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "ipip",
"DirectRouting": true
}
}ipip模式类似于vxlan模式,不过这个是三层封装三层网络。原理如组网模式所示。
[root@localhost ~]# ip route add 172.16.3.0/24 via 192.168.56.6 dev tunl0 src 192.168.56.6 onlinkipip模式下的路由规则与vxlan的不同点在于,这块的网关地址是节点的。而vxlan中网关的地址是其他节点上的flannel.1设备。另外就是所使用的tunnel设备不同。
calico使用的不是系统默认创建的tunl0,而是自己单独创建的一个一对多的ip tunnel设备,参考这里。
其他模式
hos-gw模式与vxlan模式的DirectRouting原理相同。
udp模式性差,不推荐使用了。
云控制器模式支持阿里,腾讯的vpc路由模式,简单来说就是调用云平台的api创建子网的路由规则,规则中的网关地址为节点的地址。
其他说明
flannel会将整个集群的网络划分为和主机关联的子网段,每个节点上pod的ip地址分配都是在这个子网段内划分。对于如何划分子网段,flannel提供了两种方式,一种是直接使用kubernetes为节点分配的PodCidrs字段,另外一种是使用etcd存储子网信息。
在使用PodCidrs字段时,这个字段是不会发生变化的,因为这个值是节点加入集群时分配的,不可修改。
在使用etcd为节点分配子网段的方式下,每个节点关联的子网是有一定时限的,默认是24h,超过了的话,该节点上的子网会重新申请,该节点上pod也需要重新创建。在正常情况下,只要节点上的flannel的正常运行就会自动续约这个子网的租期。如果flannel在etcd上根据ip地址查找租约找不到时,会尝试用之前的的子网进行续约(但是这块没看到有对比ip地址是否还一样的逻辑,难道是考虑主机ip地址可能变化?但是也没有在申请子网的时候有特殊处理,所以这块简单比较子网可能会导致和其他节点的冲突)。如果不想让节点管理的子网过期,可通过这个命令“etcdctl set -ttl 0 /coreos.com/network/subnets/10.5.1.0-24″设置永不过期,这样这个子网就永远属于这个节点。