最近在看cilium和calico关于eBPF功能,发现有许多不理解的地方,比如概念原理等,因此花费了一定的时间进行了学习和整理,翻了不少文档和博客,最后发现还是cilium社区的这篇文章讲解的最通透,希望后来人可以静下心来把这篇文章慢慢读下来并理解。开始方向错了,其实主要两条线,一个是基于llvm的c语言编写eBPF程序,涉及到一些宏,段定义,maps定义,btf等,llvm按照一定规范为我们编译和生成elf格式的文件,另一个是iproute2/bpftool等加载器将eBPF程序加载到内核,加载工具会读取elf中的各种段信息,将其加载到内核中,此处也会涉及段名称的约定,加载工具与编译器对于btf之间的约定。明白这两块之后再看内核提供的相关辅助函数和不同的map就可以做一些特定功能的bpf程序开发了。
简介
BPF(Berkeley Packet Filter ),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。1992 年,Steven McCanne 和 Van Jacobson 写了一篇名为《BSD数据包过滤:一种新的用户级包捕获架构》的论文。在文中,作者描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据;
由于这些巨大的改进,所有的 Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍使用该实现。 2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、网络数据包过滤、系统调用过滤,系统观测和分析等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。 eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。 此处,我们主要关注网络相关的内容。在linux内核网络协议栈中有多个网络钩子,数据包在进入到网卡再到流出网卡的过程会触发这些钩子上注册的回调函数执行相关过滤动作。如netfilter框架中的5个钩子,针对ip数据包进行过滤。除此之外,在更低一层还有xdp和tc系统对数据包进行处理。
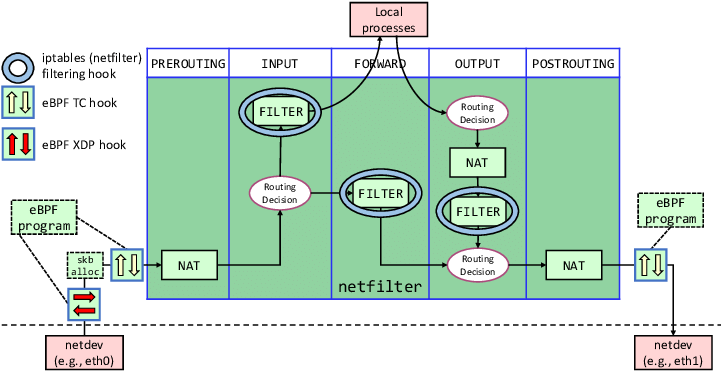
xdp和tc
xdp是是一个数据包接收处理框架,在数据包达到网卡之后,进入网络层之前会经过xdp系统进行处理,可以是丢弃,允许通过或者是转发,按照数据包流经的路径,可以有3类对数据包的卸载处理,对数据包处理可以有这几种类型:
- 网卡硬件 数据包一到达网卡,就由网卡硬件本身做卸载,比如丢弃,允许通过
- 网卡驱动 在网卡驱动层面做处理,这个位置可以拿到数据包的大小等元数据信息
- 通用卸载 在数据包进入到网络层之前,这个位置可以拿到数据包的大小等元数据信息
xdp框架会调用ebpf程序对数据包进行上述处理,因此我们可以在ebpf程序中实现诸如网络策略,负载均衡等功能。 tc是linux内核中用于数据包流量调度的功能组件,支持入站和出站数据包的流量调度。此处是可以拿到数据包的更多信息,如ip地址,tc也会调用ebpf程序对数据包进行处理,tc钩子位于数据包进入网络层之前,因此可以做到数据包绕过netfilter框架。 calico使用tc实现kubernetes服务的负载均衡,网络策略和链接跟踪功能,使用xdp实现Dos防护,入站负载均衡,对于kubernetes,xdp通常结合硬件和驱动有更高的性能。
ebpf程序
要运行ebpf程序,首先需要我们开发一个ebpf程序,开发ebpf程序可以使用多种语言,如基于bcc开发python和lua的程序,或者基于llvm的c语言程序。ebpf程序通过这些工具编译成字节码后被加载到内核中进行运行。
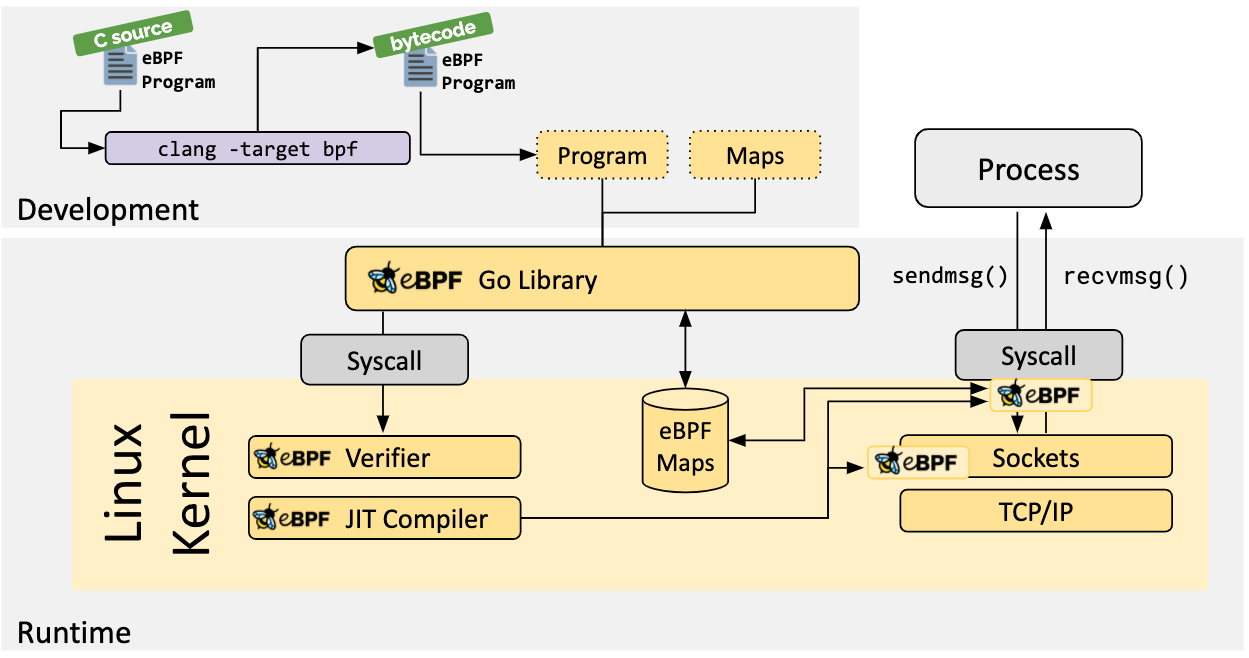
ebpf程序加载到内核之后运行之前需要对程序做验证,以避免程序崩溃或对系统造成影响,或者程序执行不会退出等情况。
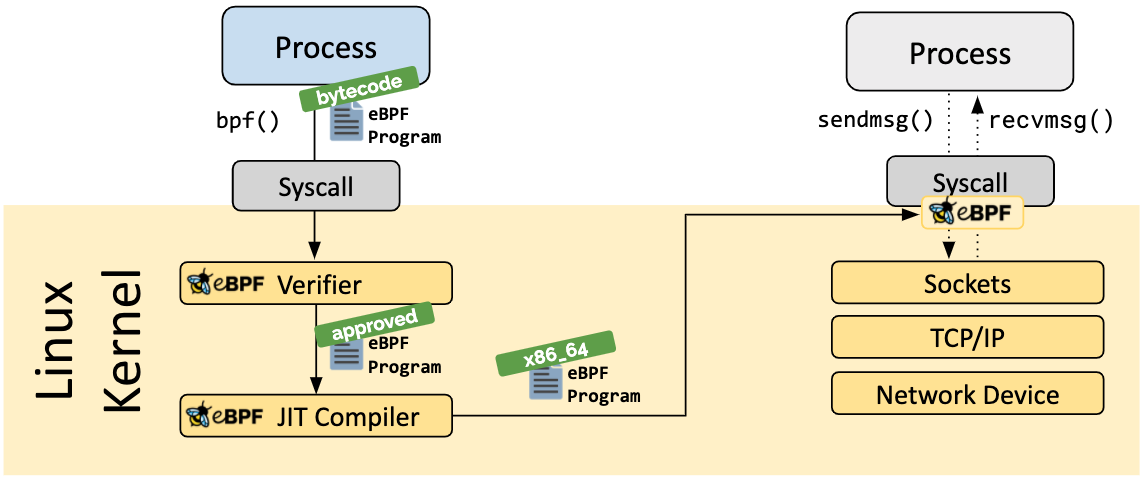
接下来就是通过JIT编译器将字节码转换成机器指令以提高执行效率,然后将程序指令挂载到指定的钩子上以被触发执行。 默认情况下,linux对编译出来字节码通过解释执行,如果设置了/proc/sys/net/core/bpf_jit_enable=1则会对字节码进行jit即时编译生成本机cpu架构的指令集,可以提高执行效率。jit编译实际上就是对原始字节码进行一对一翻译,将其转换成本机cpu架构的真实指令集。此时ebpf程序就像是内核原生代码一样执行用户编写的特定功能。但是ebpf程序里只能调用有限的内核功能,加上Verifier做的各种检查可以保证这个ebpf不会对系统造成影响。 对于ebpf程序,虽然可以生成本机字节码去执行,但依然认为他是一个在沙箱环境中执行的,因为它只能执行有限的经过验证的指令。ebpf程序可以使用内核提供的辅助函数执行一些特定功能。但是ebpf并不能直接调用这些函数,如果bpf要调用这些函数的话,需要使用ebpf call指令,首先需要把上面辅助函数里的函数id和参数放入加载到ebpf寄存器中,然后执行ebpf call指令,内核根据函数id找到实际的函数,并将其他寄存器的值传递给真正的函数,在函数执行结束后,将返回值加载到ebpf的寄存器中。 除了可以调用辅助函数之外,ebpf程序还可以调用程序内部的函数(子程序)以复用代码,这种方式和普通函数调用类似。此外,ebpf程序还可以通过尾调用机制调用其他ebpf程序,尾调用不会从其他函数返回到当前函数类似于goto语句,尾调用会保留当前栈上的数据。这三种调用拥有三种不同的指令对应。
ebpf map
ebpf map是内核提供的高效存储引擎。ebpf程序可以使用该引擎存储状态信息。用户空间程序也可以访问该引擎,该存储引擎可以和任意ebpf程序或用户空间程序共享。 存储可分为通用类型存储和非通用类型存储。通用类型包括BPF_MAP_TYPE_HASH, BPF_MAP_TYPE_ARRAY, BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_LRU_HASH, BPF_MAP_TYPE_LRU_PERCPU_HASH and BPF_MAP_TYPE_LPM_TRIE,这些类型使用共同的辅助函数进行更删改查操作。 非通用存储引擎包括BPF_MAP_TYPE_PROG_ARRAY, BPF_MAP_TYPE_PERF_EVENT_ARRAY, BPF_MAP_TYPE_CGROUP_ARRAY, BPF_MAP_TYPE_STACK_TRACE, BPF_MAP_TYPE_ARRAY_OF_MAPS, BPF_MAP_TYPE_HASH_OF_MAPS。如BPF_MAP_TYPE_PROG_ARRAY是一个存储其他ebpf程序的数组。 具体不同map的不同使用场景可以参考文档详细阅读。
BTF
BTF(BPF 类型格式)是一种元数据格式,对与 BPF 程序 /map 有关的调试信息进行编码。BTF 这个名字最初是用来描述数据类型。后来,BTF 被扩展到包括已定义的子程序的函数信息和行信息。 调试信息可用于 map 的更好打印、函数签名等。函数签名能够更好地实现 bpf 程序/函数的内核符号。行信息有助于生成源注释的翻译字节码、JIT 代码和验证器的日志。 BTF 规范包含两个部分:
- BTF 内核 API
- BTF ELF 文件格式
内核 API 是用户空间和内核之间的约定。内核在使用之前使用 BTF 信息对其进行验证。ELF 文件格式是一个用户空间 ELF 文件和 libbpf 加载器之间的约定。比如clang通过添加-g参数在编译时生成调试信息,调试信息放置在.BTF 和 .BTF.ext段。对于用SEC(“.maps”)的,还会生成.maps段,libbpf加载器会读取这些段信息,将相关的格式信息通过内核提供的api加载到内核中。
// #define __uint(name, val) int (*name)[val]
// #define __type(name, val) typeof(val) *name
// #define __array(name, val) typeof(val) *name[]
struct aaa {
int k;
};
struct test {
int(*type)[1];
typeof(struct aaa) *key;
};
int main(int argc, char **argv) {
}
# clang -c aaa.c -target bpf -g -o aaa.o
root@debian:~# llvm-objdump --section-headers aaa.o
aaa.o: file format elf64-bpf
Sections:
Idx Name Size VMA Type
0 00000000 0000000000000000
1 .strtab 0000008c 0000000000000000
2 .text 00000028 0000000000000000 TEXT
3 .debug_abbrev 0000004c 0000000000000000
4 .debug_info 00000079 0000000000000000
5 .rel.debug_info 000000c0 0000000000000000
6 .debug_str 00000042 0000000000000000
7 .BTF 000000bd 0000000000000000
8 .BTF.ext 00000060 0000000000000000
9 .rel.BTF.ext 00000030 0000000000000000
10 .debug_frame 00000028 0000000000000000
11 .rel.debug_frame 00000020 0000000000000000
12 .debug_line 0000003e 0000000000000000
13 .rel.debug_line 00000010 0000000000000000
14 .llvm_addrsig 00000000 0000000000000000
15 .symtab 00000168 0000000000000000
上面编译指令自动为函数生成了调试信息,如果想要对map也生成类型信息,可以使用下面这种定义map的方式,在cilium中基本都是用这种方式:
#include <linux/types.h>
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
struct aaa {
int k;
};
struct bbb {
int j;
};
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, struct aaa);
__type(value, struct bbb);
} MY_MAP SEC(".maps");
struct test {
int(*type)[1];
typeof(struct aaa) *key;
};
int main(int argc, char **argv) {
}
另外还可以用BPF_ANNOTATE_KV_PAIR()宏为特定maps添加类型解释。当程序或map加载之后可以通过下面命令查看其类型信息
bpftool map dump id 386
bpftool prog show id 72
bpftool btf show
bpftool btf dump id 60 format c
关于btf的详细信息可参考:https://www.kernel.org/doc/html/latest/bpf/btf.html,但是对于编写ebpf程序而言不用太多关心。
工具/库
libbpf/bpftool 项目地址:https://github.com/libbpf/libbpf。该项目是通过scripts/sync-kernel.sh脚本自动同步的linux源码中得tools/lib/bpf目录和一些依赖的头文件,源码中也包含一些该库提供给我们使用的头文件,其中比较经常使用的头文件如下:
该头文件中定义了一些常用的宏,比如SEC宏声明段的名称,__always_inline宏声明内联代码,__uint、__type和__array使用btf功能。
该头文件为我们定义了内核头文件中声明的各种函数,其中每个函数都是使用这种形式进行定义,我们知道每个函数其实都是指针,那么这里就是将这个函数指针直接指定了一个地址,这个的地址的值和内核头文件中的函数号相同,这些函数在生成eBPF指令的时候就编程了call 1或call 2等这种指令。
/*
* bpf_map_lookup_elem
*
* Perform a lookup in *map* for an entry associated to *key*.
*
* Returns
* Map value associated to *key*, or **NULL** if no entry was
* found.
*/
static void *(*bpf_map_lookup_elem)(void *map, const void *key) = (void *) 1;
libbpf提供了一些加载bpf程序的方法,封装了内核提供的bpf()系统调用,帮助我们省去了大部分关于bpf本身的逻辑。通过前面的示例我们知道bpf程序编译后生成了一个object文件,这个文件是elf格式的可执行文件,该文件中包含了很多段,这些段是通过编译器指令生成的,也就是SEC()宏生成的。那么libbpf库中提供的装载函数会使用这些段的信息。 libbpf会根据我们段的名称自动推测我们的bpf程序要挂载哪个位置,下面是一些段名对应的默认配置:
# https://github.com/libbpf/libbpf/blob/master/src/libbpf.c
static const struct bpf_sec_def section_defs[] = {
SEC_DEF("socket", SOCKET_FILTER, 0, SEC_NONE | SEC_SLOPPY_PFX),
SEC_DEF("kprobe/", KPROBE, 0, SEC_NONE, attach_kprobe),
SEC_DEF("uprobe/", KPROBE, 0, SEC_NONE),
SEC_DEF("kretprobe/", KPROBE, 0, SEC_NONE, attach_kprobe),
SEC_DEF("uretprobe/", KPROBE, 0, SEC_NONE),
SEC_DEF("tc", SCHED_CLS, 0, SEC_NONE),
SEC_DEF("classifier", SCHED_CLS, 0, SEC_NONE | SEC_SLOPPY_PFX),
SEC_DEF("action", SCHED_ACT, 0, SEC_NONE | SEC_SLOPPY_PFX),
SEC_DEF("tracepoint/", TRACEPOINT, 0, SEC_NONE, attach_tp),
SEC_DEF("tp/", TRACEPOINT, 0, SEC_NONE, attach_tp),
...
}
以SEC_DEF("sockops", SOCK_OPS, BPF_CGROUP_SOCK_OPS, SEC_ATTACHABLE_OPT | SEC_SLOPPY_PFX)来说,如果看到了名称为”sockops”的段则认为其为SOCK_OPS类型的bpf程序,期望的attach类型BPF_CGROUP_SOCK_OPS,libbpf会自动执行这些操作,否则的话就需要我们通过原生的bpf()系统调用去做这些所有事情。通过bpftool这种工具也可以让我们自定义指定这些参数。 对于map的定义和使用,我们可以通过SEC(“maps”)和SEC(“.maps”)宏进行修饰。 下面是calico和cilium针对BPF_MAP_TYPE_PROG_ARRAY类型的map的定义。
// loader在加载maps定义是根据struct结构体字段的顺序来读取字段的
// 所以eBPF程序中自己定义的结构体只要类型和顺序和加载器支持的类型一样就行
//
// bpftool(libbfp)中的map定义如下,参考https://github.com/libbpf/libbpf/blob/master/src/libbpf.h:
// struct bpf_map_def {
// unsigned int type;
// unsigned int key_size;
// unsigned int value_size;
// unsigned int max_entries;
// unsigned int map_flags;
// };
//
// iproute2中的map定义如下,参考https://git.kernel.org/pub/scm/network/iproute2/iproute2.git/tree/include/bpf_elf.h
// struct bpf_elf_map {
// __u32 type;
// __u32 size_key;
// __u32 size_value;
// __u32 max_elem;
// __u32 flags;
// __u32 id;
// __u32 pinning;
// __u32 inner_id;
// __u32 inner_idx;
// };
//
// calico的BPF_MAP_TYPE_PROG_ARRAY定义兼容bpftool的loader和iproute2的loader
// calico自己定义的map如下,参考https://github.com/projectcalico/felix/blob/master/bpf-gpl/bpf.h
// struct bpf_map_def_extended {
// __u32 type;
// __u32 key_size;
// __u32 value_size;
// __u32 max_entries;
// __u32 map_flags;
// #if defined(__BPFTOOL_LOADER__) || defined (__IPTOOL_LOADER__)
// __u32 map_id;
// #endif
// #ifdef __IPTOOL_LOADER__
// __u32 pinning_strategy;
// __u32 unused1;
// __u32 unused2;
// #endif
// };
struct bpf_map_def_extended __attribute__((section("maps"))) cali_jump = {
.type = BPF_MAP_TYPE_PROG_ARRAY,
.key_size = 4,
.value_size = 4,
.max_entries = 8,
#if !defined(__BPFTOOL_LOADER__) && defined(__IPTOOL_LOADER__)
.map_id = 1,
.pinning_strategy = 1 /* object namespace */,
#endif
};
// cilium的定义
// cilium自己的定义的bpf_elf_map如下,参考bpf/include/bpf/loader.h
// struct bpf_elf_map {
// __u32 type;
// __u32 size_key;
// __u32 size_value;
// __u32 max_elem;
// __u32 flags;
// __u32 id;
// __u32 pinning;
// __u32 inner_id;
// __u32 inner_idx;
// };
// 遵循iproute2的loader规范
// bpf/lib/maps.h
struct bpf_elf_map __section_maps POLICY_CALL_MAP = {
.type = BPF_MAP_TYPE_PROG_ARRAY,
.id = CILIUM_MAP_POLICY,
.size_key = sizeof(__u32),
.size_value = sizeof(__u32),
.pinning = PIN_GLOBAL_NS,
.max_elem = POLICY_PROG_MAP_SIZE,
};
上面是calico和cilium如何通过maps段定义prog map,那么有了这个map就可以定义这个map下的程序了,这样我们的eBPF程序就可以通过tail call调用到这些程序了。但是根据使用的加载器不同,程序添加到map的方式也不同。iproute2支持我们将程序自动加载到对应的map中,而bpftool的话则需要手动指定相关参数。 iproute2/tc 对于PROG_ARRAY,iproute2工具支持我们可以通过SEC(“1/0”),SEC(“1/1”)等定义我们的bpf PROG_ARRAY,iproute2工具会自动解析”1/0″,用1作为map的id进行查找,0作为PROG在map中的index。iproute2也是迁移到了libbpf,但是保留了这个功能,同时上面的section的默认推断配置在iproute2里也可使用。
static int find_legacy_tail_calls(struct bpf_program *prog, struct bpf_object *obj)
{
unsigned int map_id, key_id;
const char *sec_name;
struct bpf_map *map;
char map_name[128];
int ret;
/* Handle iproute2 tail call */
sec_name = get_bpf_program__section_name(prog);
ret = sscanf(sec_name, "%i/%i", &map_id, &key_id);
if (ret != 2)
return -1;
ret = iproute2_find_map_name_by_id(map_id, map_name);
if (ret < 0) {
fprintf(stderr, "unable to find map id %u for tail call\n", map_id);
return ret;
}
map = bpf_object__find_map_by_name(obj, map_name);
if (!map)
return -1;
/* Save the map here for later updating */
bpf_program__set_priv(prog, map, NULL);
return 0;
}
上面讲解到了.maps段和maps段,那么在什么情况下使用maps段呢,根据阅读calico和cilium的代码发现,如果我们想要得到更丰富的调试信息就使用.maps段,而如果我们定义的是一个PROG_ARRAY的话并且使用iproute2工具,那么则可以使用maps段,这样可以帮助我们自动将程序加载到map中。 在讲解完针对maps段加载的原理,我们可以参考一下bpftool和ip命令的详细参数了:
ip link set dev eth0 xdp obj test.o sec .text
tc qdisc add dev em1 clsact
tc filter add dev em1 ingress bpf da obj tc-example.o sec ingress
https://man7.org/linux/man-pages/man8/ip-link.8.html
https://docs.cilium.io/en/v1.9/bpf/
示例代码
下面是cilium中对上面我们提到内容的一些示例代码
// bpf/include/bpf/section.h
#ifndef __section_tail
#define __section_tail(ID, KEY) __section(__stringify(ID) "/" __stringify(KEY))
#endif
#ifndef __section_maps_btf
# define __section_maps_btf __section(".maps")
#endif
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__type(key, struct ipv4_revnat_tuple);
__type(value, struct ipv4_revnat_entry);
__uint(pinning, LIBBPF_PIN_BY_NAME);
__uint(max_entries, LB4_REVERSE_NAT_SK_MAP_SIZE);
} LB4_REVERSE_NAT_SK_MAP __section_maps_btf;
// bpf/lib/ids.h
#define CILIUM_MAP_POLICY 1
// bpf/lib/maps.h
struct bpf_elf_map __section_maps POLICY_CALL_MAP = {
.type = BPF_MAP_TYPE_PROG_ARRAY,
.id = CILIUM_MAP_POLICY,
.size_key = sizeof(__u32),
.size_value = sizeof(__u32),
.pinning = PIN_GLOBAL_NS,
.max_elem = POLICY_PROG_MAP_SIZE,
};
// bpf/bpf_xdp.c
__section("from-netdev")
int bpf_xdp_entry(struct __ctx_buff *ctx)
{
return check_filters(ctx);
}