kwok是Kubernetes WithOut Kubelet的缩写,意思是无需要kubelet的kubernetes,kwok可轻松部署数千节点的集群。通过kwok的控制器,实现让这些节点模拟真实节点的行为,从而做到在普通笔记本上部署大规模集群,帮助我们对一些核心组件进行性能测试。还有一个类似的工具叫做kubemark,虽然这个也不真实运行容器,但是要模拟多个节点需要多个kubemark实例,仍然会需要大量内存。
安装
安装docker。
这里,我们不使用官方的release版本,而是下载kwok代码到本地编译,此处我们需要修改一些参数配置,方便我们的测试。这里使用的是0.5分支,修改下列位置,主要添加了/debug/*接口跳过鉴权和调整client-go客户端qps配置(默认为50):
diff --git a/pkg/kwokctl/components/kube_scheduler.go b/pkg/kwokctl/components/kube_scheduler.go
index 07316fd..9541186 100644
--- a/pkg/kwokctl/components/kube_scheduler.go
+++ b/pkg/kwokctl/components/kube_scheduler.go
@@ -115,7 +115,7 @@ func BuildKubeSchedulerComponent(conf BuildKubeSchedulerComponentConfig) (compon
if conf.SecurePort {
if conf.Version.GE(version.NewVersion(1, 13, 0)) {
kubeSchedulerArgs = append(kubeSchedulerArgs,
- "--authorization-always-allow-paths=/healthz,/readyz,/livez,/metrics",
+ "--authorization-always-allow-paths=/healthz,/readyz,/livez,/metrics,/debug/*",
)
}
diff --git a/pkg/kwokctl/runtime/scheduler.go b/pkg/kwokctl/runtime/scheduler.go
index f23701a..09bd9d0 100644
--- a/pkg/kwokctl/runtime/scheduler.go
+++ b/pkg/kwokctl/runtime/scheduler.go
@@ -30,6 +30,7 @@ func (c *Cluster) CopySchedulerConfig(oldpath, newpath, kubeconfig string) error
err = c.AppendToFile(newpath, []byte(fmt.Sprintf(`
clientConnection:
kubeconfig: %q
+ qps: 1000
`, kubeconfig)))
if err != nil {
return err构建项目,得到./bin/linux/amd64/kwokctl:
make build事先拉取如下镜像,并导入到当前主机中。
- registry.k8s.io/etcd:3.5.9-0
- registry.k8s.io/kube-apiserver:v1.28.4
- registry.k8s.io/kube-controller-manager:v1.28.4
- registry.k8s.io/kube-scheduler:v1.28.4
- registry.k8s.io/kwok/kwok:v0.5.0 prom/prometheus:v2.45.3
为kube-scheduler使用自定义配置,方便后面对其配置进行调整,将下列内容保存到kube-scheduler.yaml:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
#percentageOfNodesToScore: 20
#parallelism: 64启动集群:
./bin/linux/amd64/kwokctl create cluster --name=kwok --etcd-image=registry.k8s.io/etcd:3.5.9-0 --kube-apiserver-image=registry.k8s.io/kube-apiserver:v1.28.4 --kube-controller-manager-image=registry.k8s.io/kube-controller-manager:v1.28.4 --kube-scheduler-image=registry.k8s.io/kube-scheduler:v1.28.4 --kwok-controller-image=registry.k8s.io/kwok/kwok:v0.5.0 --prometheus-image=prom/prometheus:v2.45.3 --prometheus-port 9090 --kube-scheduler-port 10259 --kube-scheduler-config kube-scheduler.yaml可得到如下输出:
Cluster is creating cluster=kwok
Found env KWOK_CONTAINER_SELF_COMPOSE, use it value=true cluster=kwok
Cluster is created elapsed=0.6s cluster=kwok
Cluster is starting cluster=kwok
Cluster is started elapsed=1.5s cluster=kwok
You can now use your cluster with:
kubectl cluster-info --context kwok-kwok
Thanks for using kwok!此时集群已经启动成功,通过docker ps命令查询进程信息:
blue@debian:~/codes/kwok$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
62e802249230 prom/prometheus:v2.45.3 "prometheus --config…" 26 minutes ago Up 26 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp kwok-kwok-prometheus
c2dddbb1a313 registry.k8s.io/kube-controller-manager:v1.28.4 "kube-controller-man…" 26 minutes ago Up 26 minutes kwok-kwok-kube-controller-manager
156a5fe84ff7 registry.k8s.io/kwok/kwok:v0.5.0 "kwok --manage-all-n…" 26 minutes ago Up 26 minutes kwok-kwok-kwok-controller
517caec7298c registry.k8s.io/kube-scheduler:v1.28.4 "kube-scheduler --ku…" 26 minutes ago Up 26 minutes kwok-kwok-kube-scheduler
2276dfa47cf7 registry.k8s.io/kube-apiserver:v1.28.4 "kube-apiserver --et…" 26 minutes ago Up 26 minutes 0.0.0.0:32766->6443/tcp, :::32766->6443/tcp kwok-kwok-kube-apiserver
b695add3e142 registry.k8s.io/etcd:3.5.9-0 "etcd --name=node0 -…" 26 minutes ago Up 26 minutes 2380/tcp, 4001/tcp, 7001/tcp, 0.0.0.0:32765->2379/tcp, :::32765->2379/tcp kwok-kwok-etcd
607249aa1a86 grafana/grafana:9.4.7 "/run.sh" 15 hours ago Up 15 hours 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana通过cat ~/.kube/config命令可看到这个集群的客户端配置,如果之前这个文件已经存在并存在其他集群配置的情况下,kwokctl会将当前集群的配置添加进去,并将context设置为当前集群。
启动grafana,并配置prometheus数据源:
docker run -d --name=grafana -p 3000:3000 docker.io/grafana/grafana:9.4.7打开http://localhost:3000,并配置prometheus数据源。
创建资源
下面是两个简单的方法创建节点和pod资源。
kwokctl scale node --replicas=1000
kwokctl scale pod --replicas=10000如果要对节点配置不同的标签等,对Pod配置亲和性,优先级等,可直接通过kubectl创建Node和Pod(或Deployment)资源。如:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Node
metadata:
annotations:
kwok.x-k8s.io/node: fake
metrics.k8s.io/resource-metrics-path: /metrics/nodes/node-000000/metrics/resource
node.alpha.kubernetes.io/ttl: "0"
creationTimestamp: "2024-02-07T03:13:50Z"
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: node-000000
kubernetes.io/os: linux
kubernetes.io/role: agent
kwok.x-k8s.io/kwokctl-scale: node
node-role.kubernetes.io/agent: ""
type: kwok
name: node-100000
# ......
EOF
查看监控
在创建完Node和Pod之后,集群就已经开始对pod进行调度。此时可以打开grafana面板查看相关指标数据。首先了解下调度器中用到的各种不同指标类型。
指标类型相关说明:
Counter表示一个不断累加的计数器。
Gauge表示一个测量值。
Histogram代表直方图,它有一个基础名称,并基于这个名字生成三个_sum、_count、_bucket不同的指标,分别表示观测值的总和,观测事件的总次数和按照不同时间统计的累积统计信息。
比如有一个监控api请求时长的指标,一共发起了100个请求,其中50个在0.1秒内处理完成,所有100个请求都在0.2秒之内完成(包括0.1),那么prometheus中可能记录的结果则为:
api_duration_sum 13
api_duration_count 100
api_duration_bucket{le=”0.1″} 50
api_duration_bucket{le=”0.2″} 100
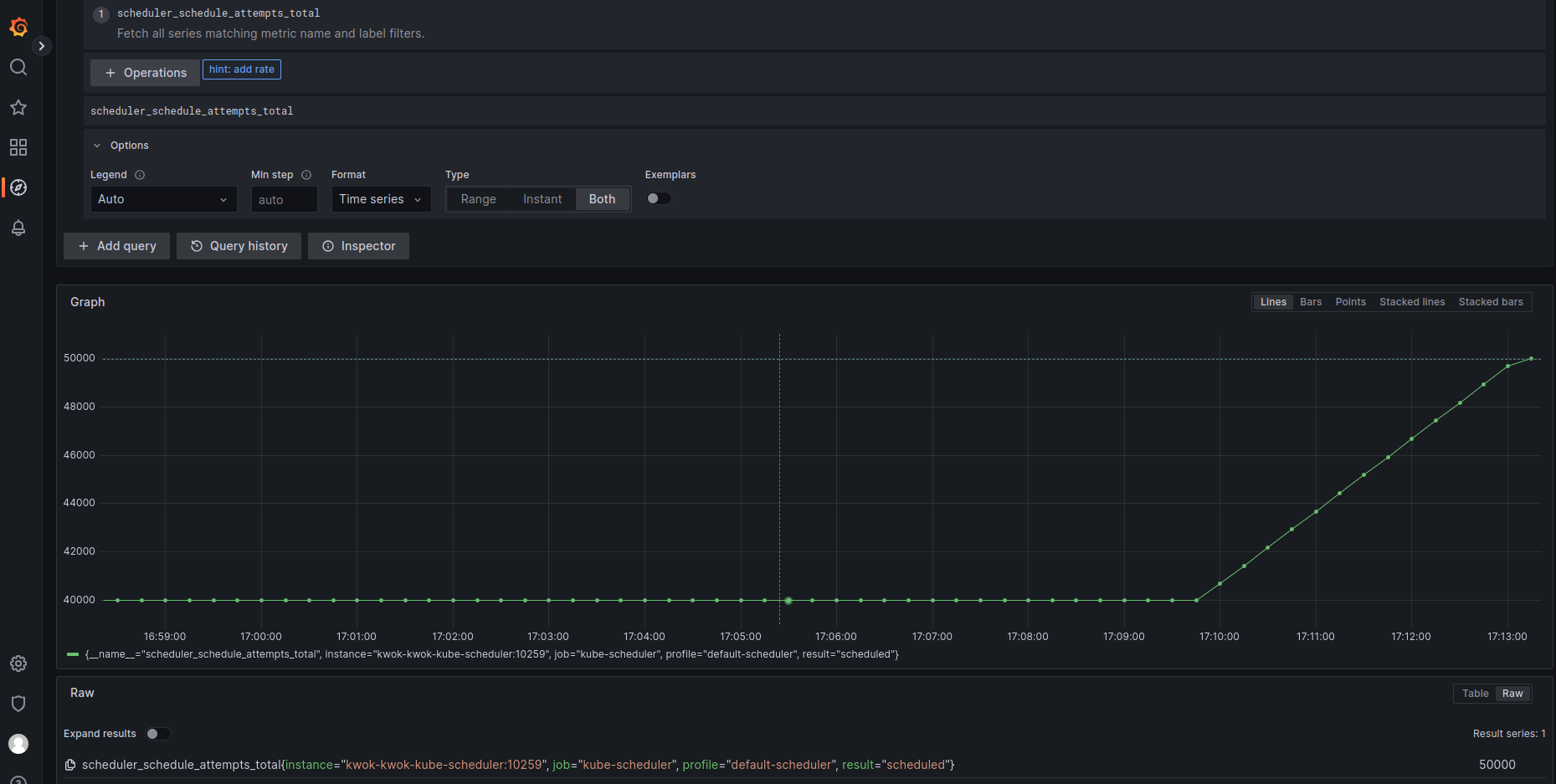
scheduler_schedule_attempts_total (CounterVec)
表示scheduleOne的总调度次数,按照scheduled,unschedulable和error统计。示例:
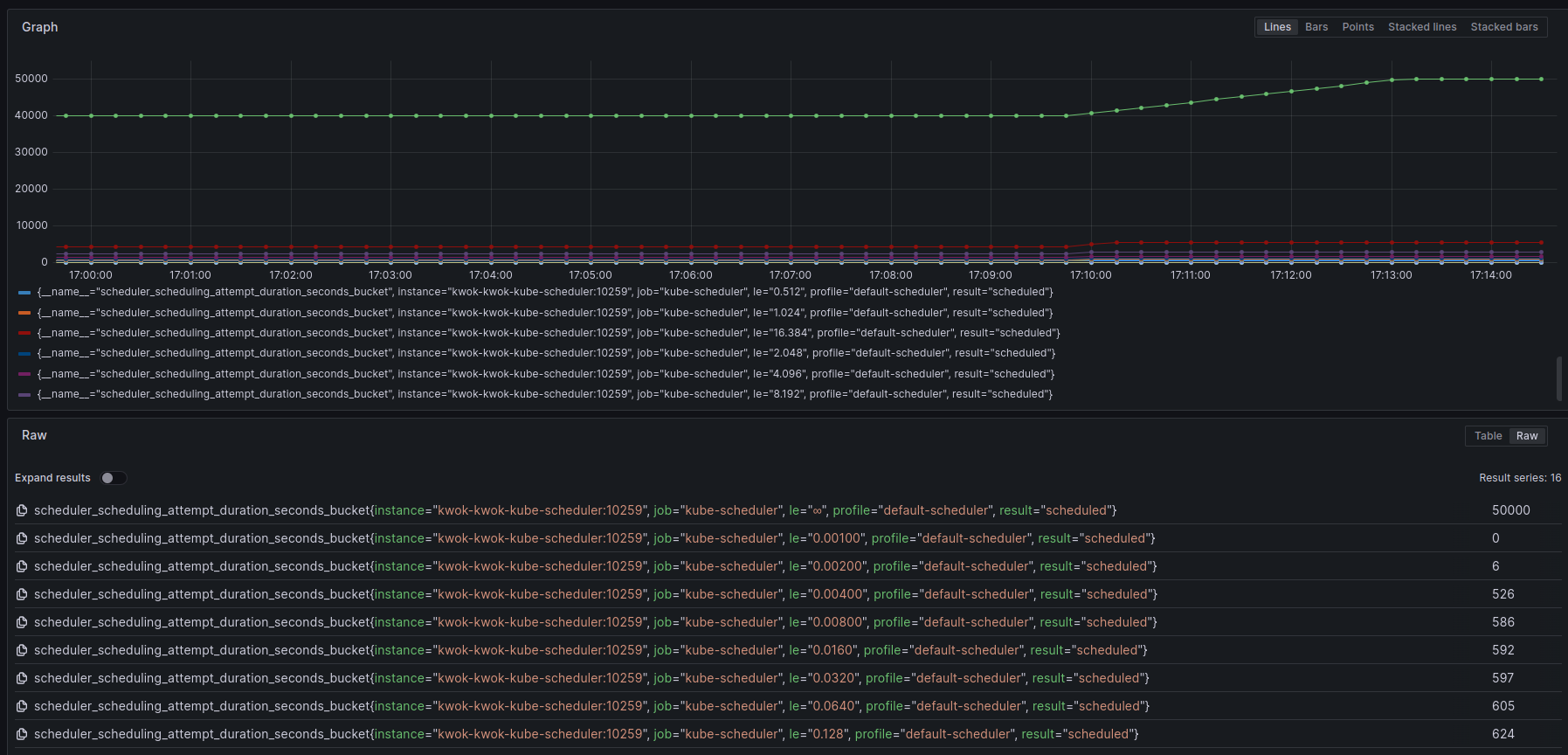
scheduler_scheduling_attempt_duration_seconds(HistogramVec)
表示scheduleOne每次尝试调度时从开始到结束的时间(覆盖调度算法和绑定过程),按照示scheduled,unschedulable和error进行统计,单位秒。示例:
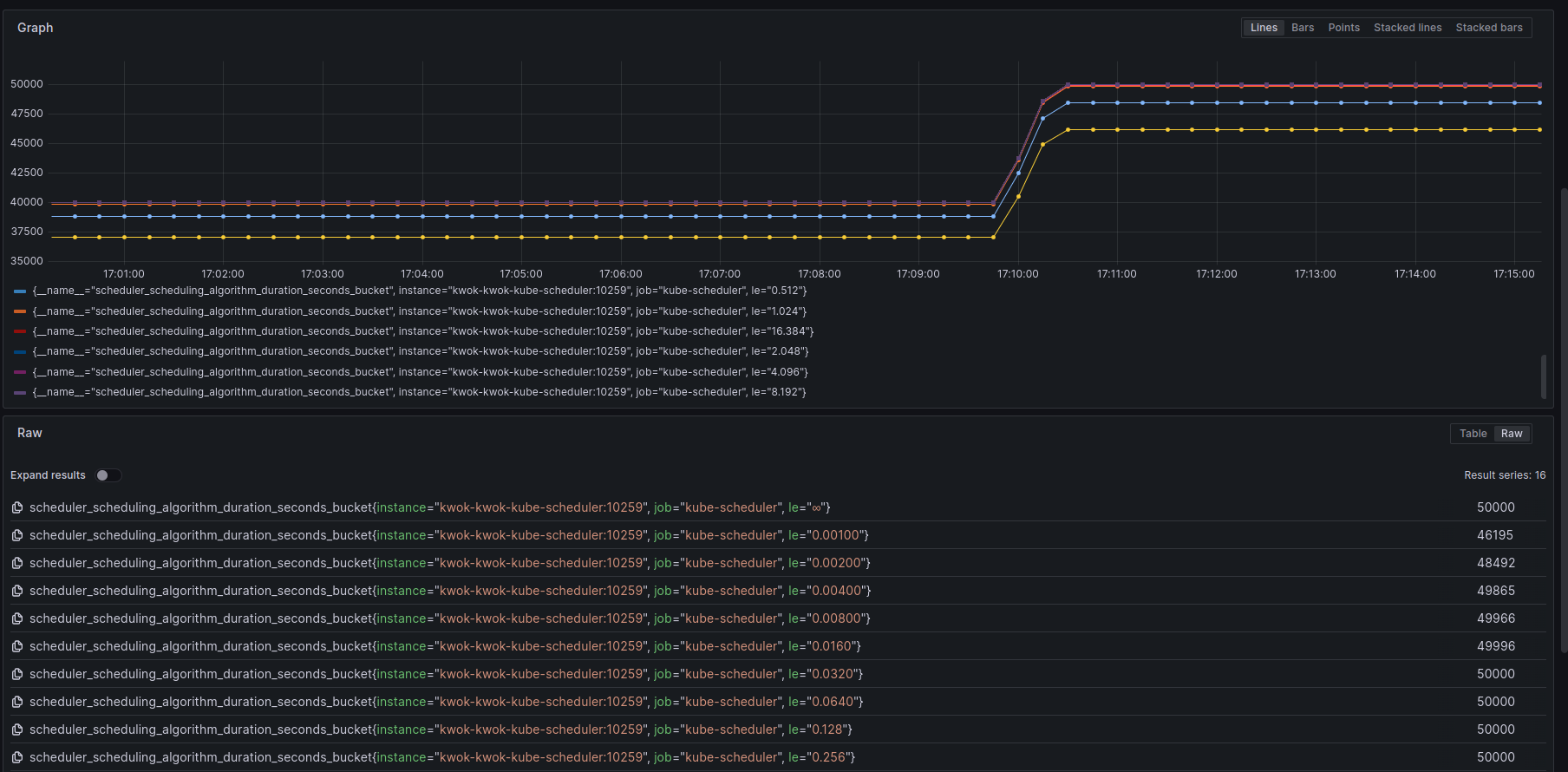
scheduler_scheduling_algorithm_duration_seconds(Histogram)
表示scheduleOne在为每个pod进行过滤和打分阶段花费的时间。示例:
scheduler_scheduling_algorithm_duration_seconds_bucket{instance=”kwok-kwok-kube-scheduler:10259″, job=”kube-scheduler”, le=”0.00200″} 38858
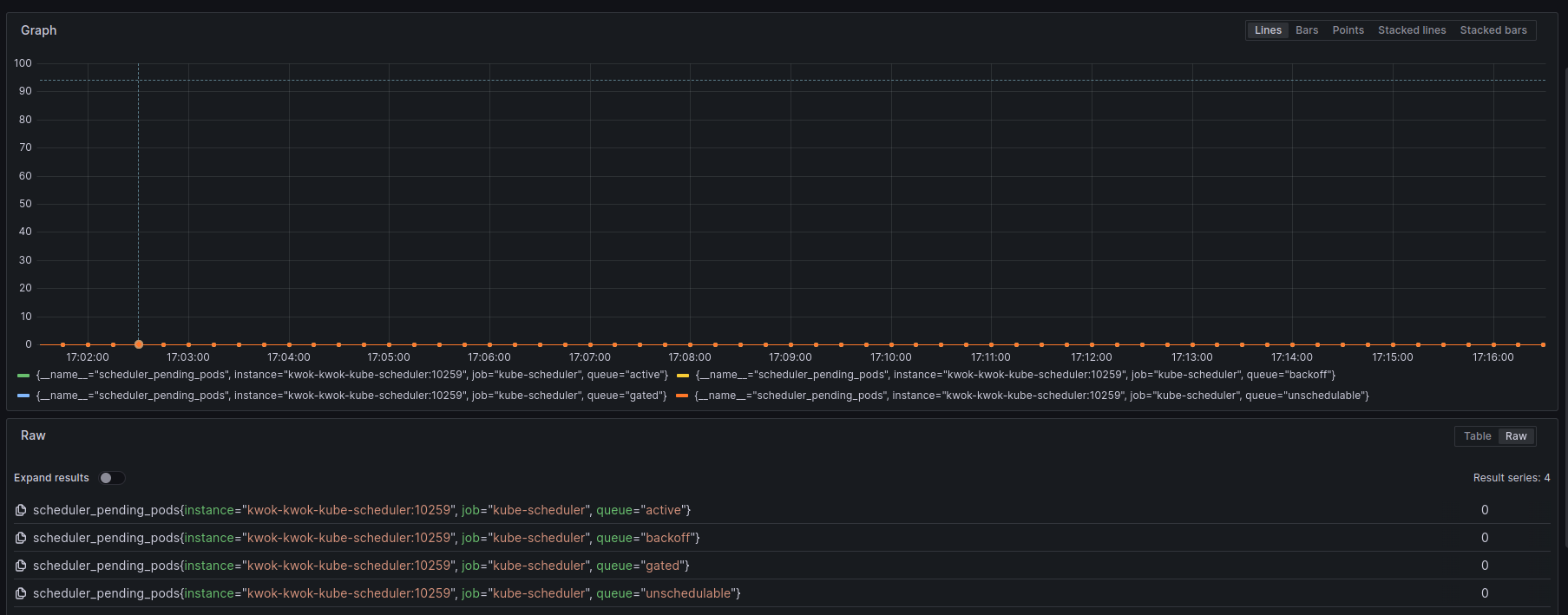
scheduler_pending_pods(Gauge)
表示在active,backoff,unschedulable和gated队列中pending的pod数量,gated表示pod还没准备好进行调度,在PreEnqueue阶段判断,参考说明。
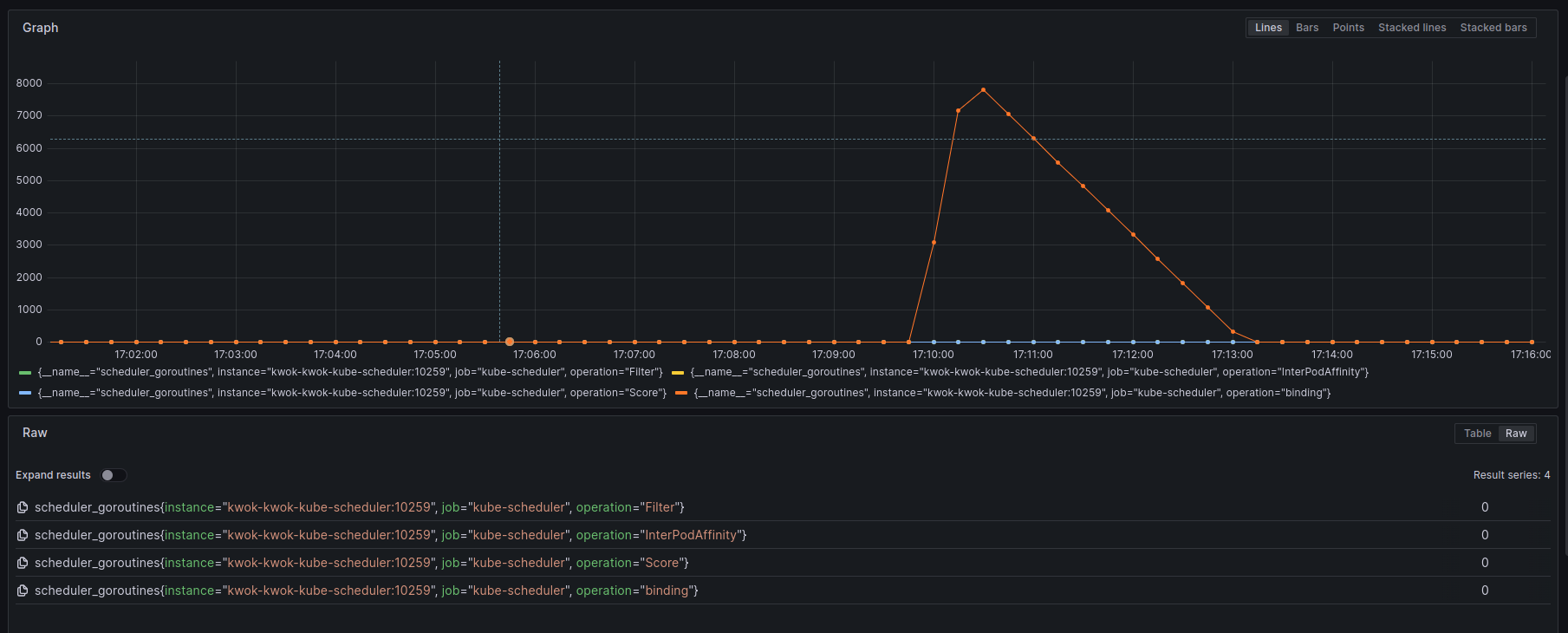
scheduler_goroutines(GaugeVec)
正在进行不同操作的goroutine的数量统计。这些操作可以是运行插件(pkg/scheduler/framework/plugins/names/names.go),执行binding等。示例:
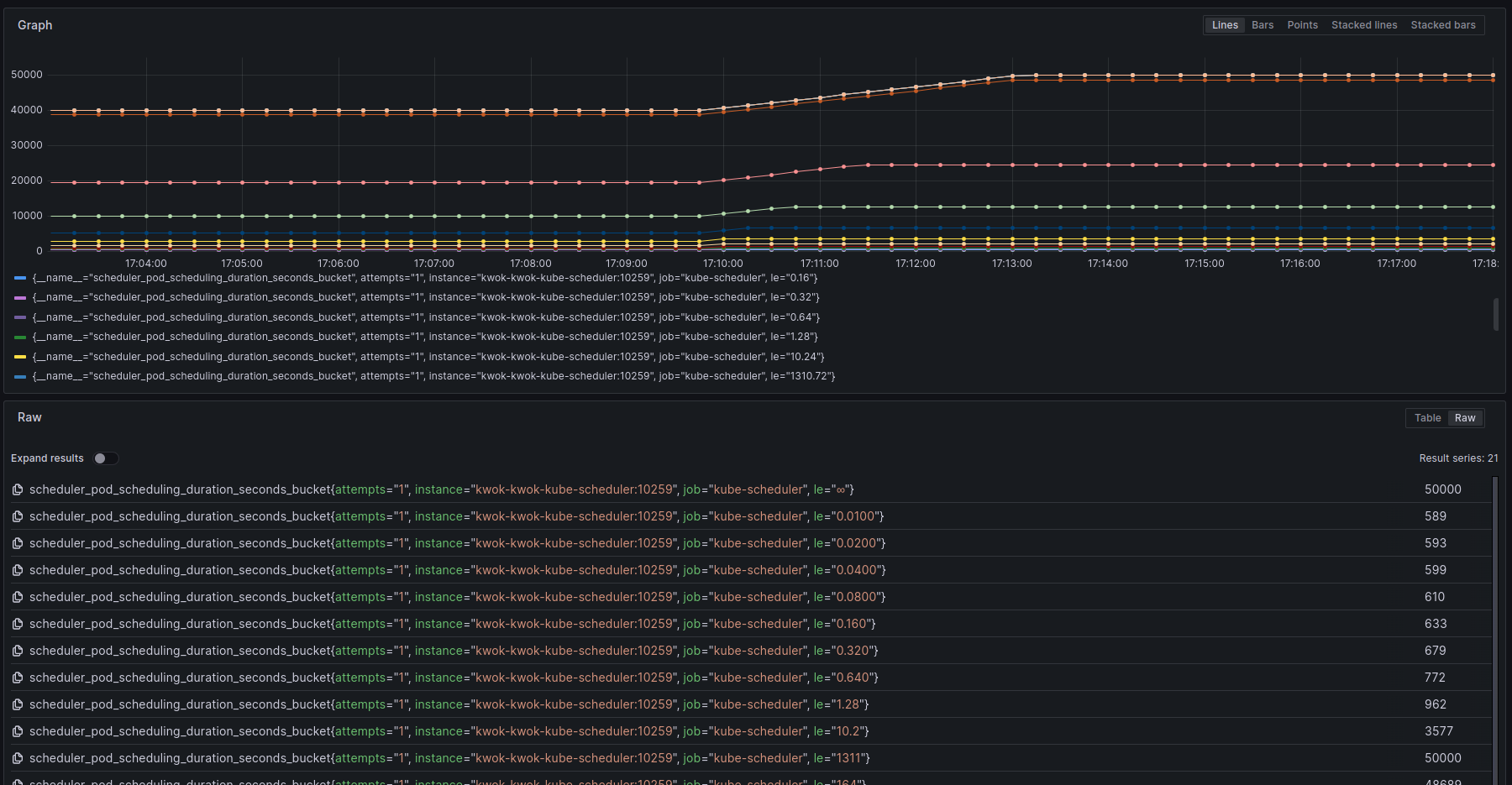
scheduler_pod_scheduling_duration_seconds(HistogramVec)
表示从pod第一次进入activeQ到调度成功(binding之后)花费的时间,可能会执行多次scheduleOne的调度尝试,所以根据调度尝试次数进行统计。单位秒。示例指标:
scheduler_pod_scheduling_duration_seconds_bucket{attempts=”1″, instance=”kwok-kwok-kube-scheduler:10259″, job=”kube-scheduler”, le=”1.28″} 769
scheduler_pod_scheduling_attempts(Histogram)
表示成功调度(binding之后)一个pod需要的调度尝试次数的统计。
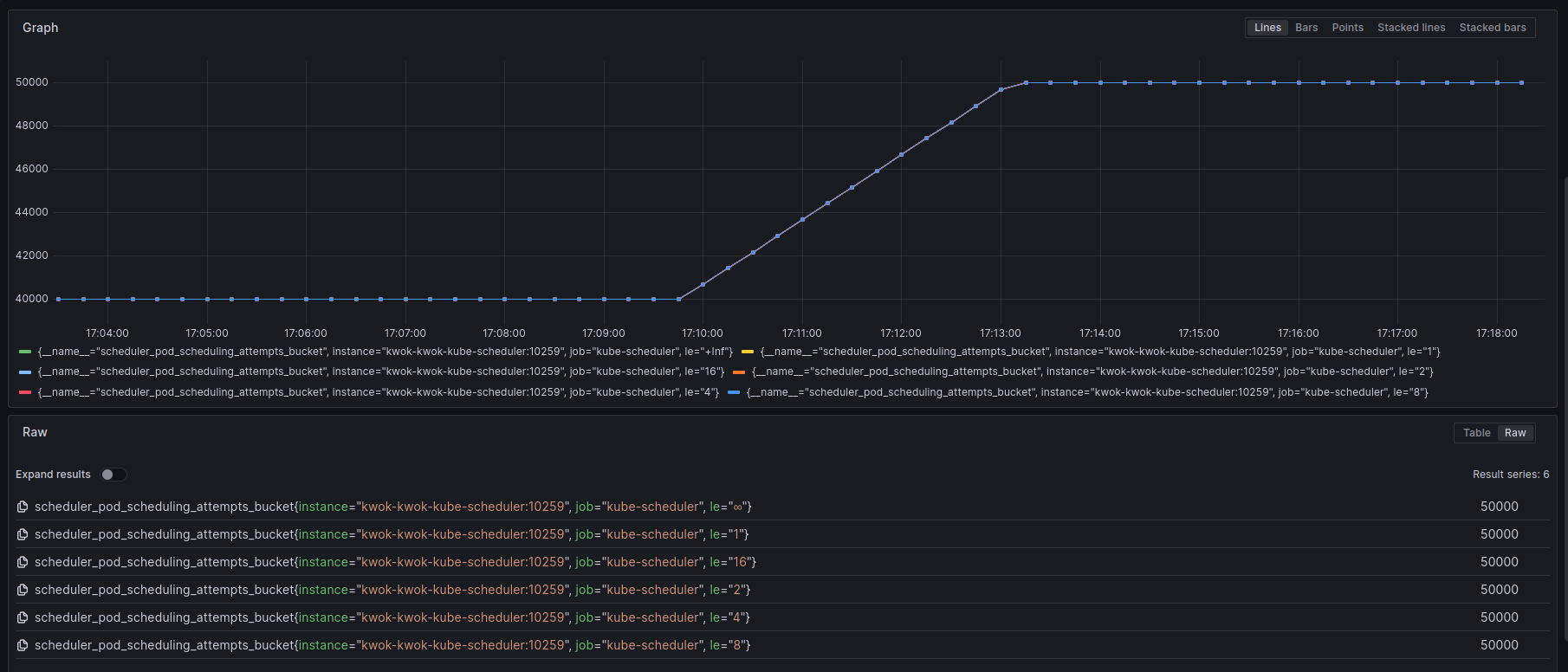
上面是我列举了一些我认为比较重要的指标,给予上面指标,其实很容易计算出kubernetes调度器当前的调度速率,可以找一些只在pod绑定成功之后才进行统计的指标,比如pod_scheduling_duration_seconds,在prometheus中可以使用rate(scheduler_pod_scheduling_duration_seconds[$__rate_interval])进行统计。
例如下面是5000节点,创建100000 pod的速率。
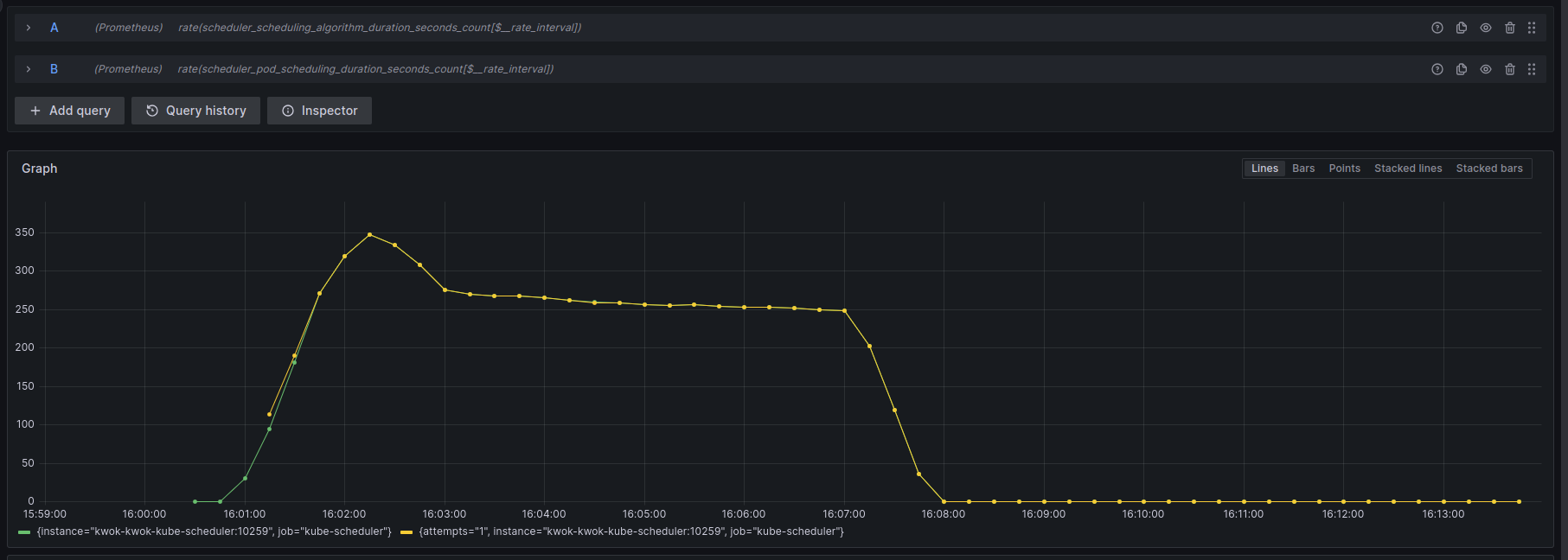
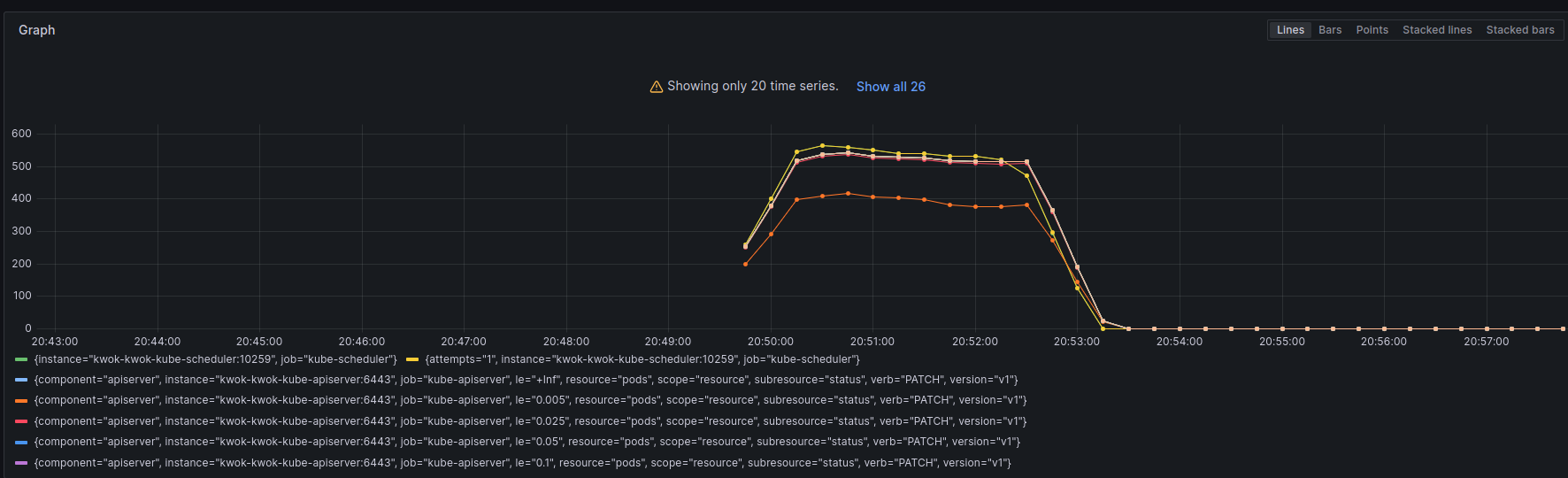
在经过一定的配置调整,先停止kube-scheduler,先创建100000个pod,在启动kube-scheduler速率还有提升,发现瓶颈是在kube-apiserver了。
获取性能数据
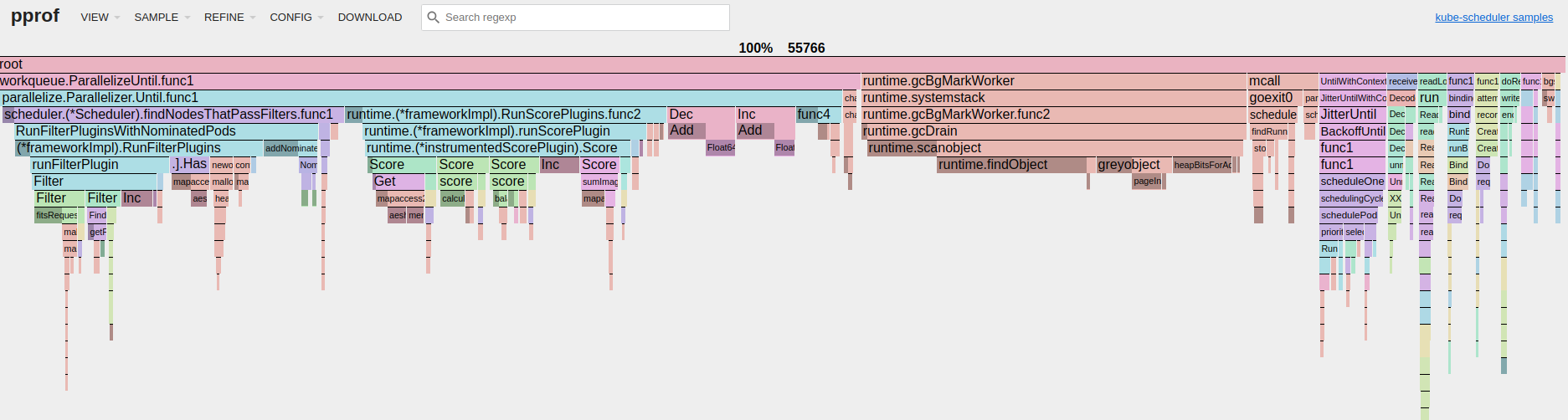
在对调度器进行压测的同时,可通过golang的pprof工具收集其性能数据,下面是命令将会对kube-scheduler进行5分钟的数据收集,完成后会自动打开浏览器显示profile数据。
go tool pprof -http localhost:12345 -seconds 300 https+insecure://localhost:10259/debug/pprof/profile例如下面是5000节点,创建100000 pod的profile。